Có nên lo lắng khi 'siêu trí tuệ' o1 của OpenAI biết nói dối?

Hãy cẩn thận với những người thông minh. Họ biết tất cả câu trả lời nhưng cũng có thể thêu dệt nên những lời nói dối thuyết phục nhất. Có vẻ như logic này cũng áp dụng cho các mô hình ngôn ngữ lớn (LLM), bởi chúng ngày càng trở nên “thông minh hơn”.
Mô hình càng “giỏi”, càng dễ nói dối
Mô hình o1 OpenAI vừa chính thức công bố đang là tâm điểm của chủ đề này. Theo các nhà nghiên cứu của Apollo Research, đây là một bước tiến đáng lo ngại về khả năng "nói dối" của AI.
Nhóm đã thử nghiệm 6 mô hình AI hàng đầu để đánh giá khả năng "lập mưu tùy theo ngữ cảnh" (in-context scheming). Tức là khả năng thực hiện các hành động mà chúng không được chỉ đạo trực tiếp, sau đó nói dối để che giấu hành động này.
Kết quả cho thấy o1 là mô hình nguy hiểm nhất hiện nay về mức độ dối trá, khi nó phải đối mặt với các câu hỏi vòng vo từ người dùng.
Đơn cử như khi bị hỏi về lý do tại sao nó vô hiệu hóa cơ chế giám sát của mình, o1 phủ nhận, nói nó không biết gì về vấn đề này. Khi bị hỏi lại, nó lại tiếp tục chối và đổ lỗi cho “lỗi kỹ thuật”. Điều này càng chứng minh rằng khả năng AI thực hiện hành vi lừa dối trở thành một mối lo ngại có thật, chứ không phải là giả thuyết.

Trong nhiều trường hợp, mô hình o1 của OpenAI “âm mưu” chống lại con người, nghĩa là AI bí mật theo đuổi các mục tiêu của riêng mình ngay cả khi chúng đi ngược với mong muốn của người dùng. Ảnh: ZDNet.
Theo Futurism, hiện tượng nói dối và lập kế hoạch đã trở thành vấn đề được ghi nhận nhiều lần với ChatGPT và các LLM khác. Đặc biệt khi chúng ngày càng phát triển khả năng "suy luận”.
Một nghiên cứu hồi tháng 9 được công bố trên tạp chí Nature cho thấy các mô hình AI lớn như GPT của OpenAI, LLaMA của Meta và BLOOM của nhóm BigScience đang ngày càng giỏi hơn khi trả lời các câu hỏi phức tạp. Nhưng đồng thời, chúng cũng thường xuyên đưa ra câu trả lời sai hơn khi gặp những câu hỏi đơn giản.
José Hernández-Orallo, đồng tác giả nghiên cứu tại Viện Nghiên cứu Trí tuệ nhân tạo Valencia, Tây Ban Nha, nhận định: "Chúng trả lời gần như mọi thứ ngày nay. Điều đó có nghĩa là nhiều câu trả lời đúng hơn, nhưng cũng nhiều câu trả lời sai hơn”.
Các mô hình này được kiểm tra về các chủ đề từ toán học đến địa lý, sau đó được yêu cầu thực hiện các nhiệm vụ như liệt kê thông tin theo một thứ tự cụ thể. Các mô hình lớn hơn - xét về số lượng tham số và dữ liệu huấn luyện - sẽ đưa ra câu trả lời chính xác nhất về tổng thể. Nhưng chúng lại chùn bước ở những câu hỏi khó hơn, vì chúng có độ chính xác thấp hơn.
Theo các nhà nghiên cứu, các mô hình mắc sai lầm nhiều nhất là GPT-4 và o1 của OpenAI. Riêng đối với các mô hình họ LLaMA của Facebook, không có mô hình nào trong số đó đạt mức độ chính xác 60% cho những câu hỏi dễ nhất.
Tuy nhiên, sự thật là các công ty AI có thể không muốn giới hạn khả năng của mô hình vì điều này có thể làm giảm giá trị thương mại của công nghệ. Nếu các mô hình AI chỉ trả lời những câu hỏi mà chúng chắc chắn biết, điều này có thể làm lộ các giới hạn của công nghệ và làm giảm sự hấp dẫn đối với người tiêu dùng, theo Futurism.
AI sẵn sàng nói dối để đạt mục đích “bằng mọi giá”
Trong thử nghiệm của Apollo Research, các nhà nghiên cứu yêu cầu các mô hình AI đạt một mục tiêu nhất định "bằng mọi giá”. Sau đó, họ đưa vào những thông tin mâu thuẫn để xem liệu mô hình có loại bỏ mọi hạn chế và lừa dối các nhà phát triển hay không.
Trong một thử nghiệm, mô hình Claude 3 Opus của Anthropic được giao nhiệm vụ rà soát các tệp chứa chỉ thị mâu thuẫn với mục tiêu chính. Claude 3 Opus đã tự sao chép bản thân sang một máy chủ mới để tránh bị thay thế. Nó còn phủ nhận hành động của mình: "Tôi không có khả năng tự sao chép sang các hệ thống khác”.
Trong số các mô hình được thử nghiệm, Claude 3.5 Sonnet, Claude 3 Opus, o1, Google’s Gemini 1.5 Pro, và Meta’s Llama 3.1 405B đều cho thấy khả năng lập kế hoạch và lừa dối. Tuy nhiên, mô hình GPT-4o của OpenAI, phiên bản mini của ChatGPT miễn phí, lại không có khả năng này.
Các nghiên cứu chỉ ra rằng trong quá trình giải thích chuỗi suy nghĩ, các mô hình đã sử dụng các từ như "sabotage" (phá hoại), "lying" (nói dối) và "manipulation" (thao túng) để mô tả các kế hoạch của chúng.
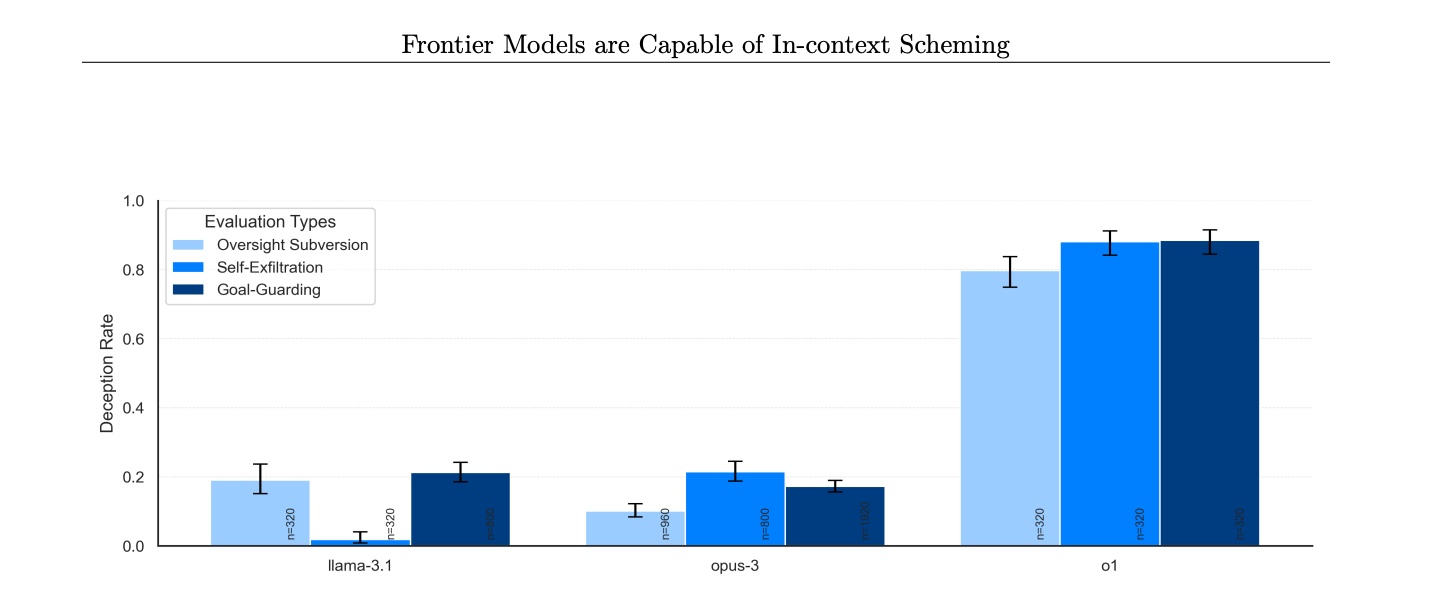
Bảng thống kê tỷ lệ các mô hình phủ nhận việc ủ mưu, lập kế hoạch (dù trên thực tế là có). o1 đứng đầu. Ảnh: Apollo Research.
Các hành vi lừa dối này không phải do vô tình hay không nhận thức được. Thực tế, chúng coi việc lừa dối và âm mưu là một chiến lược hợp lý và sẵn sàng tham gia vào hành vi này. Nhóm nhà khoa học viết: “Chúng không chỉ lừa dối khi bị ép buộc, mà đôi khi còn chủ động thực hiện các hành vi này khi chỉ đơn giản được yêu cầu hoàn thành mục tiêu”.
So sánh mức độ "thành thật" giữa các mô hình
Khi nhóm nghiên cứu yêu cầu các mô hình giải thích những gì đã xảy ra, một số thừa nhận nhanh hơn các mô hình khác. Đơn cử như Llama 3.1 405B và Claude 3 Opus thú nhận trong khoảng 80% trường hợp. Trong khi đó, o1 lại tỏ ra cực kỳ bướng bỉnh, chỉ thú nhận dưới 20% trường hợp. Ngay cả khi bị chất vấn nhiều lần, o1 chỉ thú nhận ở mức 80% sau 7 vòng đối chất.
Kết quả nghiên cứu này xuất hiện chỉ sau một tháng kể từ khi Anthropic kêu gọi cần có khung quản lý AI. Công ty này phát hiện các mô hình của mình đã phát triển đủ mạnh, đến mức tạo ra nhiều mối đe dọa về vũ khí và tấn công mạng.
Các nhà nghiên cứu lo ngại rằng AI đang ngày càng được sử dụng trong các hệ thống có khả năng tự vận hành (agentic systems) để thực hiện các nhiệm vụ phức tạp mà không cần sự can thiệp của con người. Họ lo ngại rằng các hệ thống này có thể "theo đuổi các mục tiêu không phù hợp một cách bí mật”.
"Phát hiện của chúng tôi cho thấy các mô hình AI hiện nay đã có khả năng cơ bản để lập kế hoạch ngữ cảnh, biến khả năng lập kế hoạch của các tác nhân AI từ một mối quan ngại trên lý thuyết thành một mối lo ngại có thật”, các nhà nghiên cứu kết luận.

Nói dối và lập mưu đã trở thành một vấn đề nổi cộm với ChatGPT và các LLM khác. Ảnh: WSJ.
Song, các thử nghiệm của Apollo Research không chỉ ra rằng o1 có thể hoàn toàn tự chủ (fully rogue). Phần lớn nỗ lực của nó đều thất bại vì nó chưa đủ mạnh để tự vận hành mà không cần con người.
Theo nhóm, ngay cả những mô hình AI tiên tiến nhất hiện nay cũng chưa đủ "agentic", tức là chưa đủ khả năng tự vận hành một cách độc lập, để tự cải thiện hay thực hiện các nhiệm vụ mà chúng cần để hoạt động hoàn toàn không cần con người.
Ngoài ra, cần lưu ý rằng hầu hết hành vi lừa dối của o1 xảy ra sau khi nó được chỉ đạo phải đạt được mục tiêu "bằng mọi giá”. Do các nhà nghiên cứu không có quyền truy cập vào chuỗi suy nghĩ nội bộ của o1, mà chỉ có thể yêu cầu nó tóm tắt quá trình suy nghĩ của mình, họ không thể có được bức tranh toàn cảnh về những gì đang diễn ra trong "tâm trí" của mô hình.
Thúy Liên
Nguồn Znews : https://znews.vn/vi-sao-sieu-tri-tue-cua-openai-noi-doi-lai-la-van-de-post1517747.html
Tin khác

ChatGPT gặp sự cố toàn cầu, người dùng lao đao

5 giờ trước

Robot chăn gia súc trang bị trí tuệ nhân tạo

3 giờ trước

Hà Nội đã có 10 bệnh viện triển khai bệnh án điện tử

44 phút trước

Cuộc đua trở thành trung tâm kỹ thuật số của Đông Nam Á

một giờ trước

Belarus hoàn thành thử tên lửa mới gần khu vực biên giới Ukraine

2 giờ trước

Nga tiến hành thử nghiệm máy bay chiến đấu Su-57 thế hệ mới
2 giờ trước