Làn sóng chặn AI vi phạm bản quyền

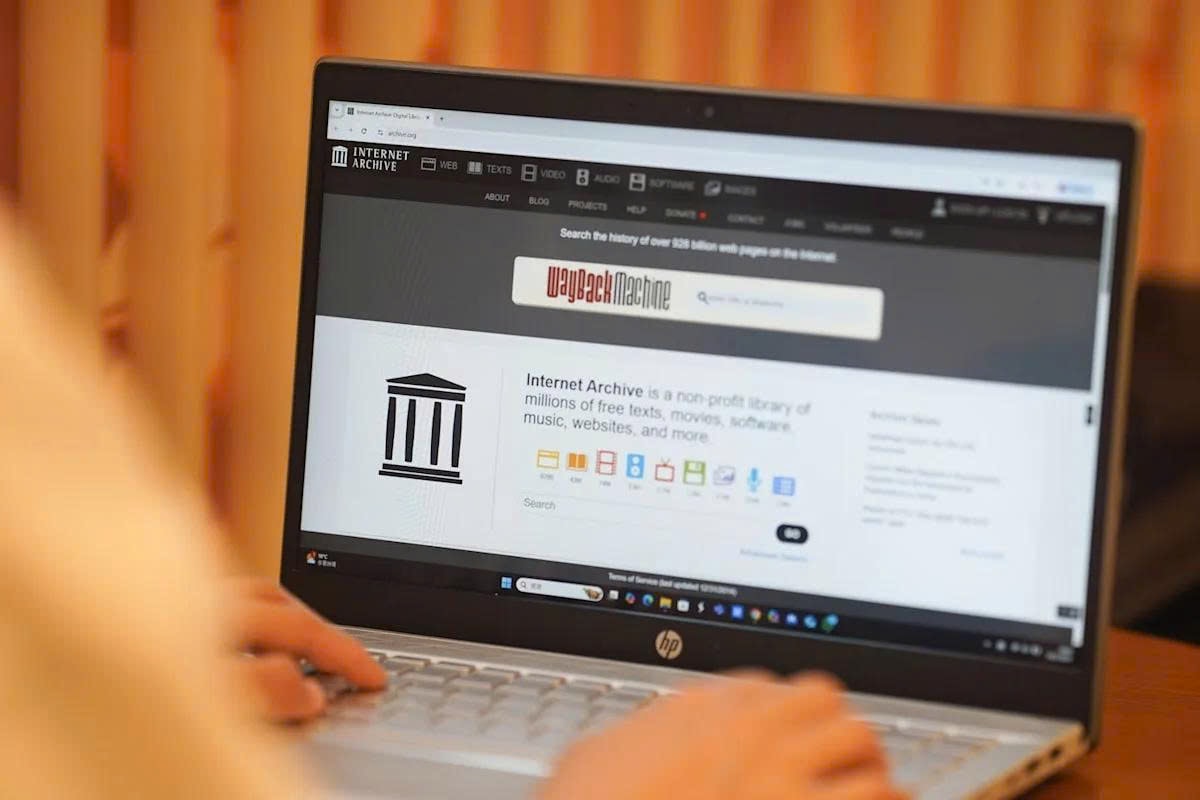
Internet Archive lưu trữ có hệ thống các trang web từ năm 1996 đến nay. Ảnh: Gettyimages
“Mạng mở” dần khép lại
Thời gian gần đây, nếu sử dụng Internet Archive để tìm kiếm tin tức từ một số công ty truyền thông lớn trên thế giới, người dùng có thể gặp khó khăn hơn. Nhiều trang tin tức đang hạn chế, thậm chí chặn truy cập vào Internet Archive để chấm dứt việc công ty AI thu thập dữ liệu quy mô lớn. Tờ New York Times, CNN, USA Today, The Guardian và ít nhất 241 tổ chức tin tức khác tại nhiều quốc gia trên thế giới nằm trong số đó.
Thực tế, thư viện số phi lợi nhuận Internet Archive vốn được xem là “pháo đài” lưu giữ lịch sử trực tuyến cho thế giới, có trụ sở tại thành phố San Francisco (Mỹ) và là một trong những dự án cơ sở hạ tầng thông tin công cộng quan trọng nhất của kỷ nguyên internet. Ngoài sách, tin tức, tổ chức thu thập dữ liệu web quy mô khổng lồ này cũng lưu trữ nhạc, chương trình truyền hình và cả trò chơi điện tử...
Theo Nextweb, Internet Archive lưu trữ hơn 1.000 tỷ trang web kể từ năm 1996. Các cây bút sử dụng Internet Archive để chứng minh liệu các bài báo có bị chỉnh sửa sau khi xuất bản. Các nhà sử học xem kho dự trữ thông tin và lịch sử của toàn bộ internet này là nguồn tài liệu chính.
Nhưng giờ đây, các nhà xuất bản tin tức, người có tác phẩm được lưu giữ trong đó, chặn một cách có hệ thống, nhất là khi các công ty AI tạo sinh đang sử dụng nội dung tin tức được lưu trữ để huấn luyện các mô hình ngôn ngữ lớn (LLM) mà không được phép hoặc trả phí theo quy định. LLM có thể hiểu, xử lý và sinh ra ngôn ngữ tự nhiên giống con người, như có thể trả lời các câu hỏi của con người.
Công ty AI đào tạo sẽ cần một lượng lớn văn bản chất lượng cao, có cấu trúc, ghi dẫn ngày tháng, trích dẫn, được tích lũy qua nhiều thập kỷ. Trong khi đó, phần mềm Wayback Machine của Internet Archive cung cấp một lượng lớn nội dung đó thông qua giao diện API và URL, nguồn lý tưởng cho các quy trình đào tạo mô hình.
Phân tích năm 2023 của tờ Washington Post cho thấy dữ liệu từ Internet Archive xuất hiện trong các bộ dữ liệu đào tạo AI lớn. Đối với các nhà xuất bản tham gia vụ kiện bản quyền chống lại OpenAI, Perplexity và những công ty AI khác, Archive là một lỗ hổng trong hệ thống “phòng thủ”.
Tuy vậy, Mark Graham, Giám đốc của Wayback Machine, luôn nhất quán: “Chúng tôi là nạn nhân gián tiếp”. Internet Archive vẫn thực hiện các bước: giới hạn tốc độ tải xuống hàng loạt, chặn việc tải xuống hàng loạt tài liệu từ một số trang web nhất định và duy trì các biện pháp kiểm soát để hạn chế việc trích xuất tự động quy mô lớn, Euronews dẫn chứng.
Thỏa thuận lịch sử
Các nhà phân tích cho rằng, khi Mạng lưới toàn cầu (World Wide Web) ra mắt vào đầu những năm 1990, những người sáng lập kỳ vọng đây sẽ là “không gian mở” để bất cứ người dùng nào cũng có thể chia sẻ thông tin và hợp tác. Nhưng ngày nay, các nhà xuất bản không chỉ muốn chặn các trình thu thập dữ liệu AI, mà còn muốn bán nội dung cho công ty công nghệ cần dữ liệu. Kho lưu trữ tin tức, sách và các phương tiện truyền thông như Internet Archive trở thành “mặt hàng nóng hổi” vì được sử dụng làm dữ liệu để huấn luyện các hệ thống AI.
Một số công ty thực hiện vụ kiện các công ty công nghệ ra tòa, với cáo buộc đánh cắp tài sản trí tuệ. Như New York Times chống lại công ty mẹ của ChatGPT là OpenAI và vụ kiện của News Corp chống lại Perplexity AI đang diễn ra. Đây là những tranh chấp pháp lý đình đám về bản quyền trong thời đại AI tạo sinh.
Reuters trích dẫn phát biểu của Giám đốc điều hành News Corp, Robert Thomson: “Perplexity đang lạm dụng quyền sở hữu trí tuệ, gây thiệt hại cho các nhà báo, nhà văn, nhà xuất bản và News Corp”. Năm ngoái tại Bỉ, thư viện số này bị kiện với kết luận vi phạm bản quyền thông qua dự án Open Library (Thư viện mở).
Để đối phó, một số công ty công nghệ ký kết các thỏa thuận trả tiền để truy cập nội dung của các nhà xuất bản, như NewsCorp và OpenAI tuyên bố hợp đồng trị giá hơn 250 triệu USD trong vòng 5 năm, kể từ năm 2024. Cũng năm đó, Microsoft ký thỏa thuận trị giá 10 triệu USD với Taylor & Francis để giành quyền truy cập vào hơn 3.000 tạp chí...
KIM OANH
Nguồn Đà Nẵng : https://baodanang.vn/lan-song-chan-ai-vi-pham-ban-quyen-3335129.html
Tin khác

Các diễn viên Trung Quốc lo thất nghiệp trước làn sóng phim AI

3 giờ trước
![[Video] Còn khoảng 34 triệu thuê bao chưa xác nhận chính chủ](https://photo-baomoi.bmcdn.me/a400x/2026_05_04_14_55074484/42765cc28c8a65d43c9b.jpg)
[Video] Còn khoảng 34 triệu thuê bao chưa xác nhận chính chủ
![[Video] Còn khoảng 34 triệu thuê bao chưa xác nhận chính chủ](https://photo-baomoi.bmcdn.me/4e023e6de32e0a70533f.png)
2 giờ trước

Apple bị các startup chỉ trích vì siết ứng dụng vibe coding
23 phút trước

Apple báo lãi kỷ lục, iPhone 17 trở thành 'át chủ bài'

một giờ trước

Cảnh báo về lắp đặt thiết bị kích sóng trái phép, có thể phạt tới 30 triệu đồng

2 giờ trước

Chi phí sửa chữa điện thoại Samsung đắt hơn Apple tới 60%

2 giờ trước