Mô hình AI mới của Apple gây ấn tượng với khả năng tạo văn bản siêu tốc

Cơ chế mới “siêu tốc độ”
Hiện tại, các mô hình ngôn ngữ mới (LLM) như ChatGPT hoạt động theo cơ chế tự hồi quy, tức là tạo văn bản một cách tuần tự, từng từ một, khiến quá trình này tốn nhiều thời gian.
Ngược lại, mô hình mới của Apple dựa trên cơ chế khuếch tán, cho phép nó tạo ra nhiều từ đồng thời và tinh chỉnh dần qua các vòng lặp. Đây chính là chìa khóa tạo nên sự khác biệt về tốc độ của mô hình mới với ChatGPT.
Thậm chí, một biến thể khác của nhóm này là mô hình khớp luồng còn tiến thêm một bước, loại bỏ hoàn toàn quá trình lặp để tạo ra kết quả chỉ trong một lần duy nhất.

Apple tăng tốc trong cuộc đua AI với mô hình khuếch tán tốc độ cao (Ảnh minh họa).
Nghiên cứu mới của Apple
Nghiên cứu mang tên “FS-DFM: Fast and Accurate Long Text Generation with Few-Step Diffusion Language Models” (Mô hình khuếch tán tạo văn bản đa bước cực ngắn), được thực hiện bởi nhóm của Apple phối hợp cùng Đại học Bang Ohio, đã giới thiệu mô hình đột phá: Few-Step Discrete Flow-Matching (FS-DFM) (Mô hình khớp luồng rời rạc).
Điểm đáng kinh ngạc là FS-DFM có thể tạo ra các đoạn văn bản dài chỉ sau 8 vòng tinh chỉnh, nhưng vẫn đạt chất lượng đầu ra tương đương với các mô hình khuếch tán khác cần đến hơn 1.000 bước để hoàn thành.
Để đạt được hiệu suất ấn tượng này, nhóm nghiên cứu đã kết hợp ba yếu tố then chốt. Trước hết là phương pháp huấn luyện đa cấp, giúp mô hình xử lý linh hoạt và hiệu quả ở nhiều mức độ tinh chỉnh khác nhau.
Tiếp đó, nhóm áp dụng “mô hình giáo viên” - một hệ thống hướng dẫn đảm bảo FS-DFM được cập nhật chính xác theo từng bước và không bị lệch khỏi mục tiêu ban đầu. Cuối cùng, họ tối ưu hóa toàn bộ vòng lặp huấn luyện, tinh chỉnh cách vận hành để rút ngắn thời gian xử lý và nâng cao độ ổn định của đầu ra.
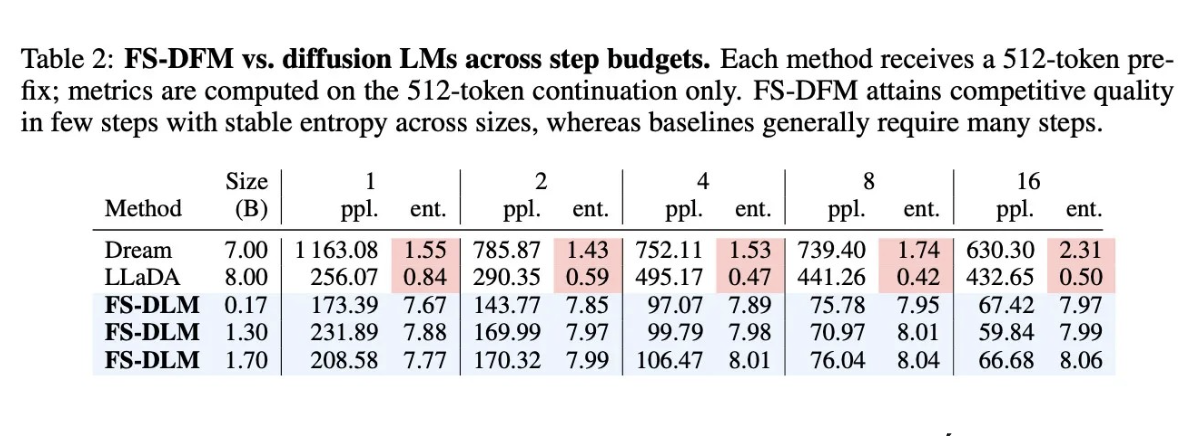
Bảng so sánh hiệu năng giữa FS-DFM và các mô hình khuếch tán khác (Ảnh: 9to5Mac).
Nhờ cách tiếp cận này, FS-DFM đã vượt qua nhiều đối thủ có quy mô lớn hơn. Trong các thử nghiệm so sánh với những mô hình khuếch tán như Dream (7 tỷ tham số) và LLaDA (8 tỷ tham số), FS-DFM chỉ từ 0,17 đến 1,7 tỷ tham số vẫn đạt kết quả nổi bật.
Cụ thể, chỉ số Perplexity thấp hơn chứng tỏ văn bản được tạo ra tự nhiên và chính xác hơn, phản ánh khả năng “hiểu” ngôn ngữ vượt trội của mô hình. Đồng thời, Entropy ổn định hơn cho thấy sự cân bằng giữa tính đa dạng và mạch lạc, giúp nội dung vừa phong phú vừa liền mạch, không rơi vào tình trạng lặp lại nhàm chán.
Mở đường cho cộng đồng AI
Nhận thấy tiềm năng vượt trội và mong muốn thúc đẩy nghiên cứu trong lĩnh vực mới mẻ này, Apple cho biết sẽ sớm công bố mã nguồn và các điểm kiểm thử mô hình. Động thái này nhằm khuyến khích cộng đồng AI toàn cầu tái tạo và mở rộng nghiên cứu, hứa hẹn một cuộc cách mạng trong việc sinh văn bản bằng trí tuệ nhân tạo.
Khánh Linh
Nguồn Xây Dựng : https://baoxaydung.vn/mo-hinh-ai-moi-cua-apple-gay-an-tuong-voi-kha-nang-tao-van-ban-sieu-toc-19225101501291585.htm
Tin khác

Apple chọn Việt Nam làm 'cứ điểm' sản xuất chiến lược cho dòng sản phẩm hoàn toàn mới

6 giờ trước

Home Hub, robot và camera Apple sẽ được sản xuất tại Việt Nam

một giờ trước

Apple sắp có bất ngờ

2 ngày trước

Chuyến thăm ít ai ngờ của Tim Cook
7 giờ trước

Nhu cầu cực mạnh của iPhone 17 đã giúp Apple bắt kịp Samsung

11 giờ trước

Soi X-quang cáp USB-C giá rẻ và cáp 129 USD của Apple

9 giờ trước