Nghiên cứu của Google: Mô hình AI tốt nhất chỉ trả lời chính xác gần 69%

Tuần này, Google DeepMind đã giới thiệu FACTS Benchmark Suite, bộ tiêu chuẩn dùng để đo lường mức độ đáng tin cậy của các mô hình AI trong việc đưa ra câu trả lời chính xác về mặt thực tế.
FACTS Benchmark Suite đánh giá mô hình trên bốn khía cạnh:
Tiêu chuẩn tham số: Đánh giá khả năng của mô hình AI trong việc trả lời chính xác câu hỏi thực tế mà không cần sự hỗ trợ từ các công cụ bên ngoài như tìm kiếm trên web. Tất cả câu hỏi trong tiêu chuẩn theo phong cách "đố vui" dựa trên sự quan tâm của người dùng, có thể được trả lời thông qua Wikipedia (một nguồn tiêu chuẩn để huấn luyện trước mô hình ngôn ngữ lớn).
Tiêu chuẩn tìm kiếm:Đánh giá khả năng mô hình AI sử dụng công cụ tìm kiếm trên web để trả lời câu hỏi. Tiêu chuẩn này được thiết kế để gây khó khăn cho các mô hình ngôn ngữ lớn ngay cả khi có quyền truy cập vào web, thường đòi hỏi phải truy xuất nhiều dữ kiện theo trình tự để trả lời một truy vấn duy nhất. Công cụ tìm kiếm trên web giống nhau được cung cấp cho tất cả mô hình AI, đảm bảo khả năng của chúng được kiểm tra một cách độc lập mà không bị yếu tố gây nhiễu từ các cài đặt truy xuất web tùy chỉnh. Tiêu chuẩn tìm kiếm gồm 890 câu hỏi trong tập công khai và 994 câu trong tập đánh giá riêng.
Tiêu chuẩn đa phương thức: Tiêu chuẩn đa phương thức đánh giá khả năng các mô hình AI tạo ra văn bản chính xác về mặt dữ kiện để phản hồi các câu hỏi dựa trên hình ảnh. Đây là một khả năng quan trọng với các mô hình đa phương thức hiện đại. Tác vụ này yêu cầu khả năng diễn giải chính xác và kết nối thông tin từ đầu vào hình ảnh, sử dụng kiến thức nội bộ về thế giới của nó. Khung đánh giá được thiết kế để đảm bảo phản hồi vừa chính xác, vừa cung cấp tất cả thông tin cần thiết để được coi là hoàn chỉnh. Tiêu chuẩn đa phương thức gồm 711 câu hỏi trong tập công khai và 811 câu trong tập đánh giá riêng.
Grounding Benchmark v2: Kiểm tra khả năng của mô hình AI trong việc trả lời đúng và bám sát ngữ cảnh của câu hỏi được đưa ra.
Theo FACTS Benchmark Suite, mô hình AI đạt kết quả tốt nhất là Google Gemini 3 Pro, với độ chính xác 68,8%. Trong khi các mô hình AI hàng đầu khác như GPT-5 (61,8%), GPT-5.1 (49,4%), Grok 4 (53,6%) và Claude 4.5 Opus (51,3%) đạt kết quả thấp hơn.
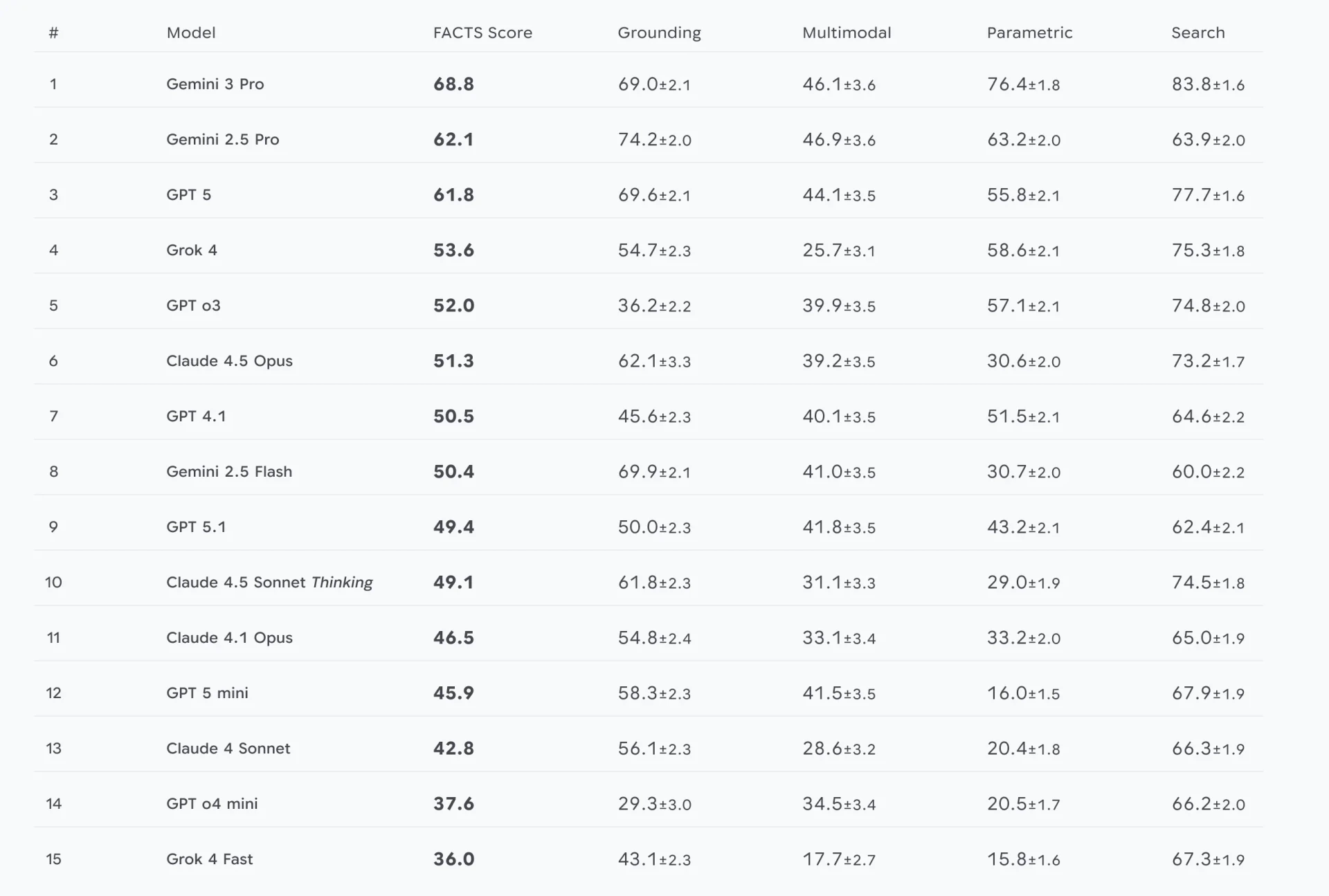
Gemini 3 Pro dẫn đầu FACTS Benchmark Suite
Con số này là vấn đề đáng quan tâm với các doanh nghiệp và những ai đang đặt cược vào AI. Dù các mô hình AI rất xuất sắc về tốc độ và sự trôi chảy trong diễn đạt, độ tin cậy về mặt dữ kiện của chúng vẫn còn kém xa so với kỳ vọng từ con người, đặc biệt trong các tác vụ liên quan đến kiến thức chuyên sâu, suy luận phức tạp hoặc dựa vào tài liệu nguồn một cách chính xác.
Ngay cả những sai sót nhỏ về mặt dữ kiện cũng có thể gây ra hậu quả lớn trong các lĩnh vực như tài chính, chăm sóc sức khỏe và pháp luật.
Melia Russell, PV trang Insider, gần đây đã xem xét cách các hãng luật đối phó với sự trỗi dậy của mô hình AI như một nguồn thông tin pháp lý đáng tin cậy. Vấn đề khá phức tạp: Cô kể lại trường hợp một công ty đã sa thải nhân viên vì nộp tài liệu chứa đầy các vụ kiện bịa đặt sau khi sử dụng ChatGPT để soạn thảo.
FACTS Benchmark Suite vừa là lời cảnh báo vừa là bản chỉ đường: Bằng cách chỉ ra cụ thể AI sai ở đâu và sai như thế nào, Google kỳ vọng sẽ thúc đẩy việc cải thiện các mô hình. Song ở thời điểm hiện tại, thông điệp được rút ra rất rõ ràng: Mô hình AI đang tiến bộ, nhưng vẫn trả lời sai khoảng 1/3 số trường hợp.
Chưa đánh giá GPT-5.2
Cần lưu ý là trong đánh giá của FACTS Benchmark Suite chưa có GPT-5.2, vừa được OpenAI trình làng hôm 12.12. OpenAI khẳng định đây là dòng mô hình AI mạnh mẽ nhất đến nay cho công việc tri thức chuyên nghiệp.
“Chúng tôi thiết kế GPT-5.2 nhằm tạo ra nhiều giá trị kinh tế hơn cho người dùng. Mô hình này giỏi hơn trong việc tạo bảng tính, xây dựng bài thuyết trình, viết mã, phân tích hình ảnh, hiểu văn bản dài, sử dụng công cụ và xử lý các dự án phức tạp gồm nhiều bước”, OpenAI thông báo.
Trong ChatGPT, phiên bản GPT-5.2 Instant, Thinking và Pro sẽ bắt đầu được triển khai từ hôm 12.12, với các gói trả phí trước tiên. Trên API, các phiên bản này hiện đã sẵn sàng cho mọi nhà phát triển.
Trong bài đánh giá hiệu năng GDPval, OpenAI cho biết GPT-5.2 có thể vượt qua “các chuyên gia trong ngành ở những nhiệm vụ công việc tri thức được mô tả rõ ràng, trải rộng trên 44 lĩnh vực nghề nghiệp”.
“GPT-5.2 Thinking tạo ra kết quả cho các nhiệm vụ GDPval với tốc độ nhanh hơn 11 lần và chi phí thấp hơn dưới 1% so với các chuyên gia. Điều này cho thấy rằng, khi có sự giám sát của con người, GPT-5.2 có thể hỗ trợ đáng kể cho công việc chuyên môn”, công ty khởi nghiệp AI số 1 thế giới thông báo.
Ngoài ra, OpenAI tiết lộ rằng trong bài kiểm tra nội bộ dành cho các tác vụ lập mô hình bảng tính của chuyên viên phân tích ngân hàng đầu tư cấp dưới, “chẳng hạn xây dựng mô hình 3 báo cáo cho một công ty Fortune 500 với định dạng và trích dẫn chuẩn, hoặc dựng mô hình LBO cho một thương vụ tư nhân hóa”, điểm số của GPT-5.2 cao hơn 9,3% mỗi tác vụ so với GPT-5.1, tăng từ trung bình 59,1% lên 68,4%. Thông tin này chắc chắn sẽ thu hút sự chú ý của các ngân hàng.
Fortune 500 là top 500 doanh nghiệp có doanh thu cao nhất nước Mỹ, bao gồm cả tập đoàn công nghệ, năng lượng, bán lẻ, tài chính, ô tô…
LBO (Leveraged Buyout) là mô hình tài chính dùng để phân tích và định giá một thương vụ thâu tóm bằng đòn bẩy. Nói đơn giản, đây là mô hình giúp trả lời câu hỏi: Nếu mua lại một công ty bằng lượng lớn tiền vay mượn, thương vụ có sinh lời hay không?
Ngoài ra, GPT-5.2 Thinking bị ảo giác (trả lời sai y như thật) ít hơn GPT-5.1 Thinking. Với người dùng chuyên nghiệp, điều này đồng nghĩa với việc ít sai sót hơn khi dùng GPT-5.2 Thinking để nghiên cứu, viết lách, phân tích và hỗ trợ ra quyết định, giúp mô hình đáng tin cậy hơn cho công việc tri thức hằng ngày.
Theo OpenAI, GPT-5.2 Thinking là mô hình thị giác mạnh nhất của công ty cho đến nay, giảm khoảng một nửa tỷ lệ lỗi trong suy luận biểu đồ và hiểu giao diện phần mềm. Với người dùng chuyên nghiệp, GPT-5.2 Thinking diễn giải chính xác hơn bảng điều khiển (dashboard), ảnh chụp sản phẩm, sơ đồ kỹ thuật và báo cáo trực quan, hữu ích trong các quy trình tài chính, vận hành, kỹ thuật, thiết kế và hỗ trợ khách hàng, nơi thông tin hình ảnh đóng vai trò chủ đạo.
Trên mạng xã hội X, OpenAI đăng ảnh cho thấy GPT-5.2 vượt GPT-5.1 và Claude Opus 4.5 của Anthropic trên 8 bài kiểm tra khác nhau. Cụ thể gồm:
SWE-Bench Pro: Đánh giá khả năng sửa lỗi và hiểu mã trong các dự án phần mềm thực tế.
GPQA Diamond: Câu hỏi khoa học nâng cao, không cho phép dùng công cụ.
CharXiv Reasoning: Phân tích biểu đồ, hình minh họa khoa học.
FrontierMath: Toán học nâng cao nhiều cấp độ khó.
AIME 2025: Bài thi toán cạnh tranh (giống Olympic).
ARC-AGI-1 và ARC-AGI-2: Bài kiểm tra về tư duy trừu tượng và suy luận logic.
GDPval: Bộ đánh giá đo lường các nhiệm vụ công việc tri thức được mô tả rõ ràng trên 44 ngành nghề.
Nếu so với Gemini 3 Pro, GPT-5.2 giành chiến thắng 7/8 bài kiểm tra, trừ CharXiv Reasoning.
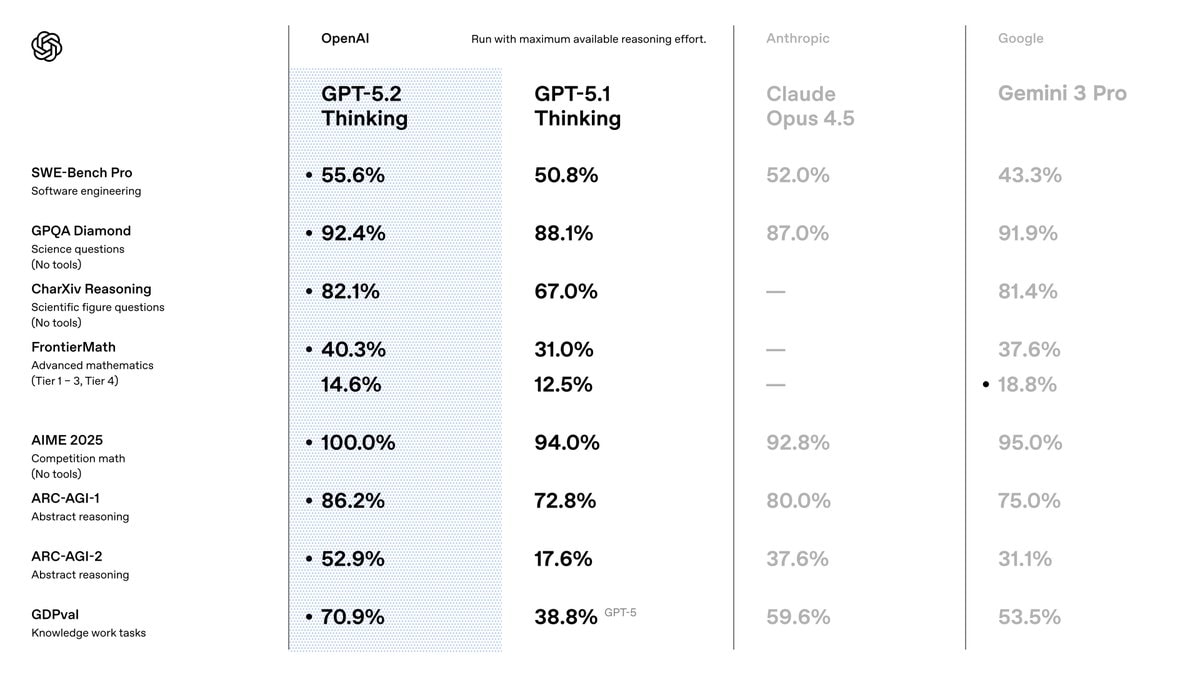
GPT-5.2 vượt Gemini 3.0 Pro và Claude Opus 4.5 ở phần lớn bài kiểm tra
Trước khi GPT-5.2 trình làng, nhiều người trong giới công nghệ nhận định Google đang đuổi kịp và thậm chí vượt OpenAI trong cuộc đua AI, với việc phát hành Gemini 3 hồi tháng 11 gây được nhiều tiếng vang.
Thế nhưng, Sam Altman (Giám đốc điều hành OpenAI) nói trong cuộc phỏng vấn với kênh CNBC hôm 11.12: “Gemini 3 gây ít ảnh hưởng đến các chỉ số của chúng tôi hơn so với lo ngại ban đầu”.
Sơn Vân
Nguồn Một Thế Giới : https://1thegioi.vn/nghien-cuu-cua-google-mo-hinh-ai-tot-nhat-chi-tra-loi-chinh-xac-gan-69-242321.html
Tin khác

Google thử nghiệm dịch trực tiếp qua tai nghe, tiến gần hơn mục tiêu xóa rào cản ngôn ngữ

2 giờ trước

Google trở thành 'ngôi sao mới' trong cuộc đua AI

một ngày trước

ChatGPT-5.2 chính thức ra mắt với 3 cải tiến đáng chú ý

một ngày trước

Gemini thử nghiệm tính năng đánh dấu trực tiếp trên hình ảnh

2 ngày trước

Điện thoại bị 'đe dọa' bởi kính thông minh của Google

4 giờ trước

'Ngày đáng tự hào' với các gia đình Australia

14 giờ trước