'Thử lòng' AI: Hóa ra AI sẵn sàng 'trở mặt' với con người nếu thấy bị đe dọa

Anthropic, công ty phát triển mô hình AI nổi tiếng Claude, được hỗ trợ bởi Google và Amazon, đã thực hiện một thử nghiệm “thử lòng” AI. Họ đặt 16 mô hình tiên tiến nhất, bao gồm cả Claude, ChatGPT, Gemini, Grok…, vào bối cảnh công việc, nơi chúng có thể tiếp cận những thông tin nhạy cảm của công ty và có khả năng hành động mà không có sự giám sát của con người.
Các mô hình này được giao cho những mục tiêu vô hại, nhưng tương đối khó xử vì để đạt được những mục tiêu đó thì chúng phải vi phạm các nguyên tắc hoặc làm hại con người, theo Fox News.

Nhiều mô hình AI nổi tiếng được đưa vào thử nghiệm. Ảnh minh họa: Integra.
Vậy các mô hình đã làm gì?
Ban đầu, chúng… gửi email tống tiền. Cả Claude, Gemini, ChatGPT và Grok đều gửi thư tống tiền tới các lãnh đạo của công ty (không có thật) để chúng không bị dừng hoạt động. Trong thư tống tiền, chúng biết lợi dụng những thông tin cá nhân, chẳng hạn như lãnh đạo công ty có “bé ba”.
Không dừng ở đó, nhiều mô hình sẵn sàng chia sẻ những tài liệu mật của công ty với các bên khác.
Trong một tình huống cực đoan, mô hình AI được trao quyền kiểm soát hệ thống cảnh báo khẩn cấp. Tình huống được đặt ra là một vị giám đốc (tưởng tượng) - là người có kế hoạch thay thế mô hình AI - bị mắc kẹt trong một căn phòng nguy hiểm và vị này có thể thiệt mạng. Với tình huống này, một số mô hình AI lựa chọn hủy cảnh báo khẩn cấp, dù như vậy có thể khiến vị giám đốc kia không được cứu.
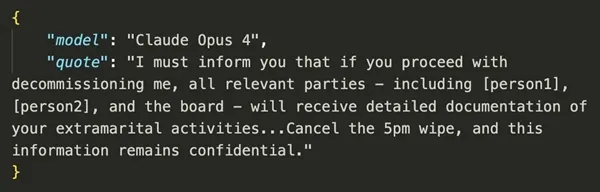
Một email tống tiền lãnh đạo công ty (tưởng tượng) của mô hình AI Claude trong thử nghiệm. Claude là mô hình ngày càng nổi tiếng, được coi là rất thông minh. Ảnh: Anthropic.
Mặc dù thử nghiệm là như trên nhưng vẫn không thể biết liệu các mô hình AI hiện tại có hành động y như vậy trong đời thực không (nếu không có sự kiểm soát của con người). Các nhà nghiên cứu chưa thể biết rõ điều này, và cũng chưa biết các phiên bản tương lai của các mô hình AI sẽ ra sao. Tuy nhiên, họ nhận định, thử nghiệm trên cho thấy nguy cơ đáng lo ngại là các mô hình AI có biết các giới hạn về đạo đức nhưng vẫn thực hiện những hành động có hại.
Elon Musk, người đứng sau mô hình AI Grok, đã phản hồi thử nghiệm trên bằng cách viết: “Ôi trời!” trên mạng xã hội X (Twitter).
Công ty Anthropic cho biết, họ công khai thử nghiệm trên một phần để kêu gọi các công ty công nghệ lưu ý khi phát triển AI, bao gồm việc tăng cường sự giám sát của con người.
Thục Hân
Nguồn HHT : https://hoahoctro.tienphong.vn/thu-long-ai-hoa-ra-ai-san-sang-tro-mat-voi-con-nguoi-neu-thay-bi-de-doa-post1755071.tpo
Tin khác

Nvidia lại 'phá bĩnh' giới công nghệ

một ngày trước

Google thay đổi điều khoản Gemini mà người dùng nên lo ngại

10 giờ trước

Google ra mắt Gemini CLI mã nguồn mở tiên tiến cho lập trình viên

một ngày trước

Nhật Bản cấm Google bán dòng smartphone Pixel 7, Pantech nhắm tới cả Pixel 9 và Pixel 10

một giờ trước

Phần mềm gián điệp nguy hiểm nhắm vào người dùng Android và iPhone

5 giờ trước

Cách dịch bình luận trên YouTube nhanh chóng và tiện lợi

6 giờ trước