AI không cần mạng của Google làm được gì?

Gemma 4 là mô hình ngôn ngữ lớn (LLM) do Google DeepMind phát triển. Đây là dòng mô hình mã nguồn mở, hỗ trợ xử lý thông tin trực tiếp trên máy mà không cần Internet. Người dùng có thể tải, tùy chỉnh và triển khai trên máy tính hay thiết bị di động thông thường.
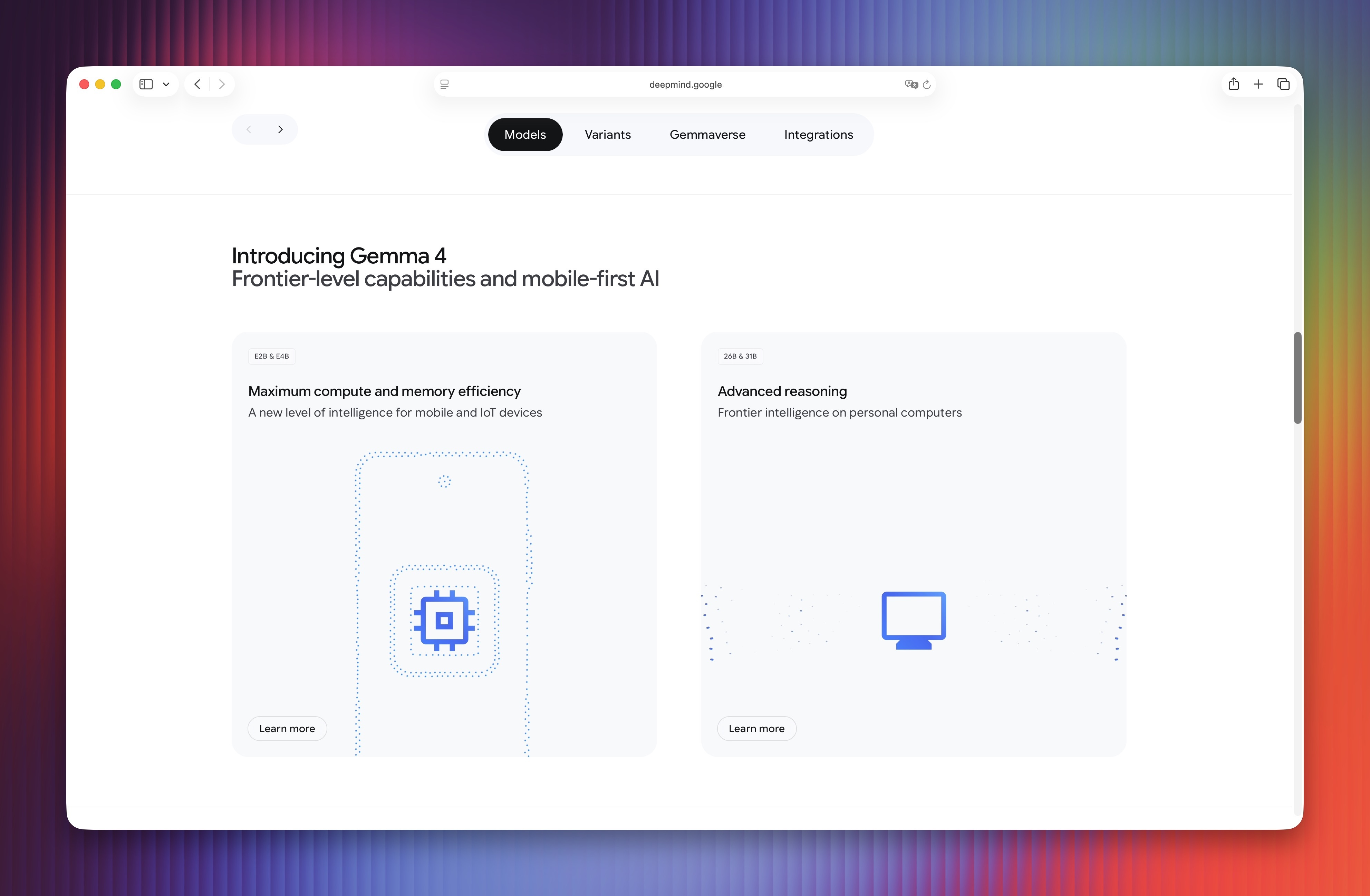
Dòng mô hình Gemma 4 được phân phối với 4 phiên bản: E2B, E4B, 31B và 26B A4B. 2 phiên bản E2B và E4B yêu cầu RAM tối thiểu 4-6 GB (4-bit) hoặc 10-16 GB (16-bit), phù hợp để chạy trên thiết bị di động và máy tính cấu hình vừa phải. Trong khi đó, phiên bản 26B A4B yêu cầu tối thiểu 18 GB RAM, còn 31B cần ít nhất 20 GB.
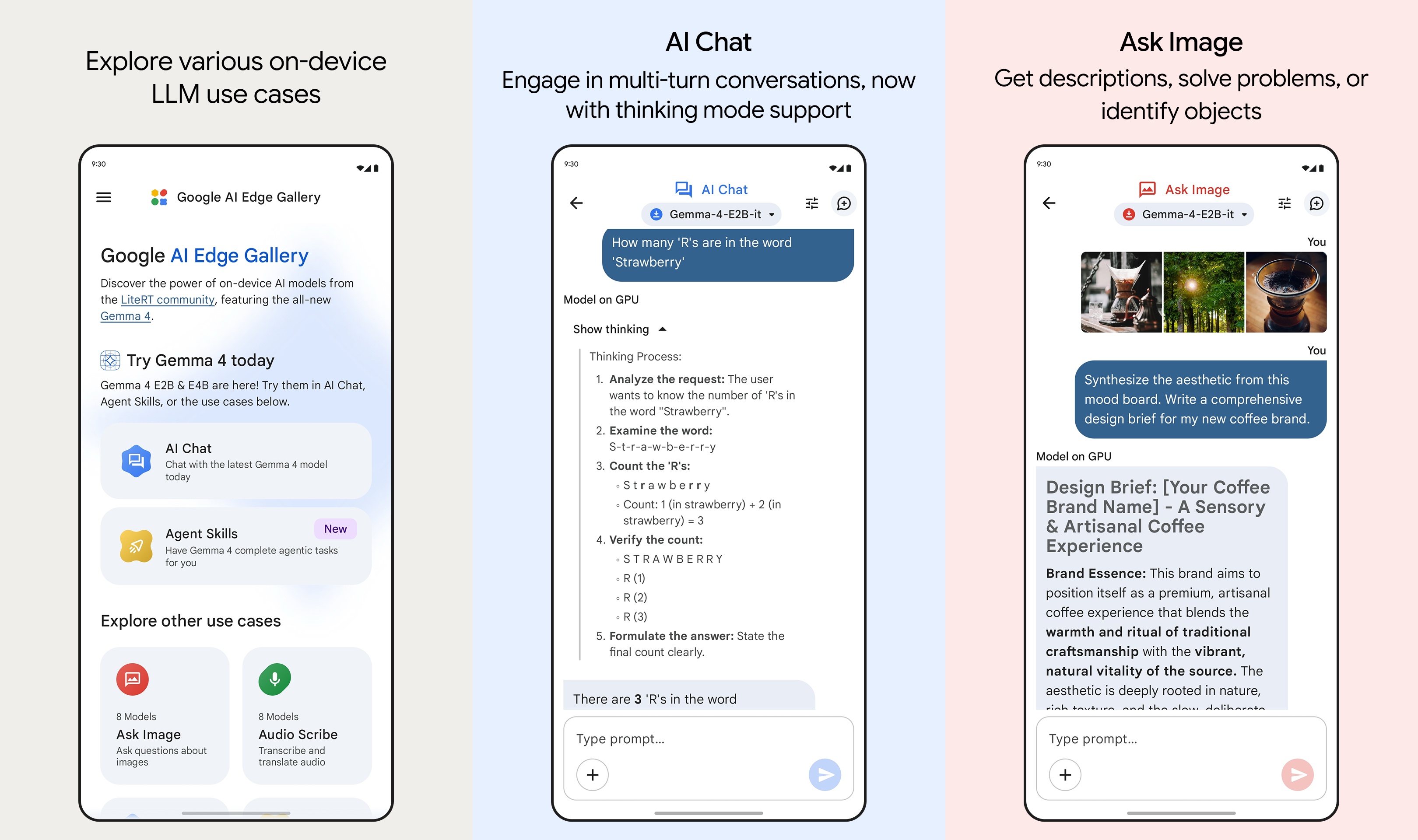
Theo MindStudio, một trong những lợi thế khi chạy mô hình AI cục bộ gồm tính bảo mật, không có chi phí bổ sung. Tuy nhiên, hiệu năng hoạt động các mô hình phụ thuộc vào phần cứng thiết bị. Người dùng di động có thể cài ứng dụng Google AI Edge Gallery (ảnh), trong khi máy tính cần các công cụ như LM Studio hay Ollama. Ảnh: Google.
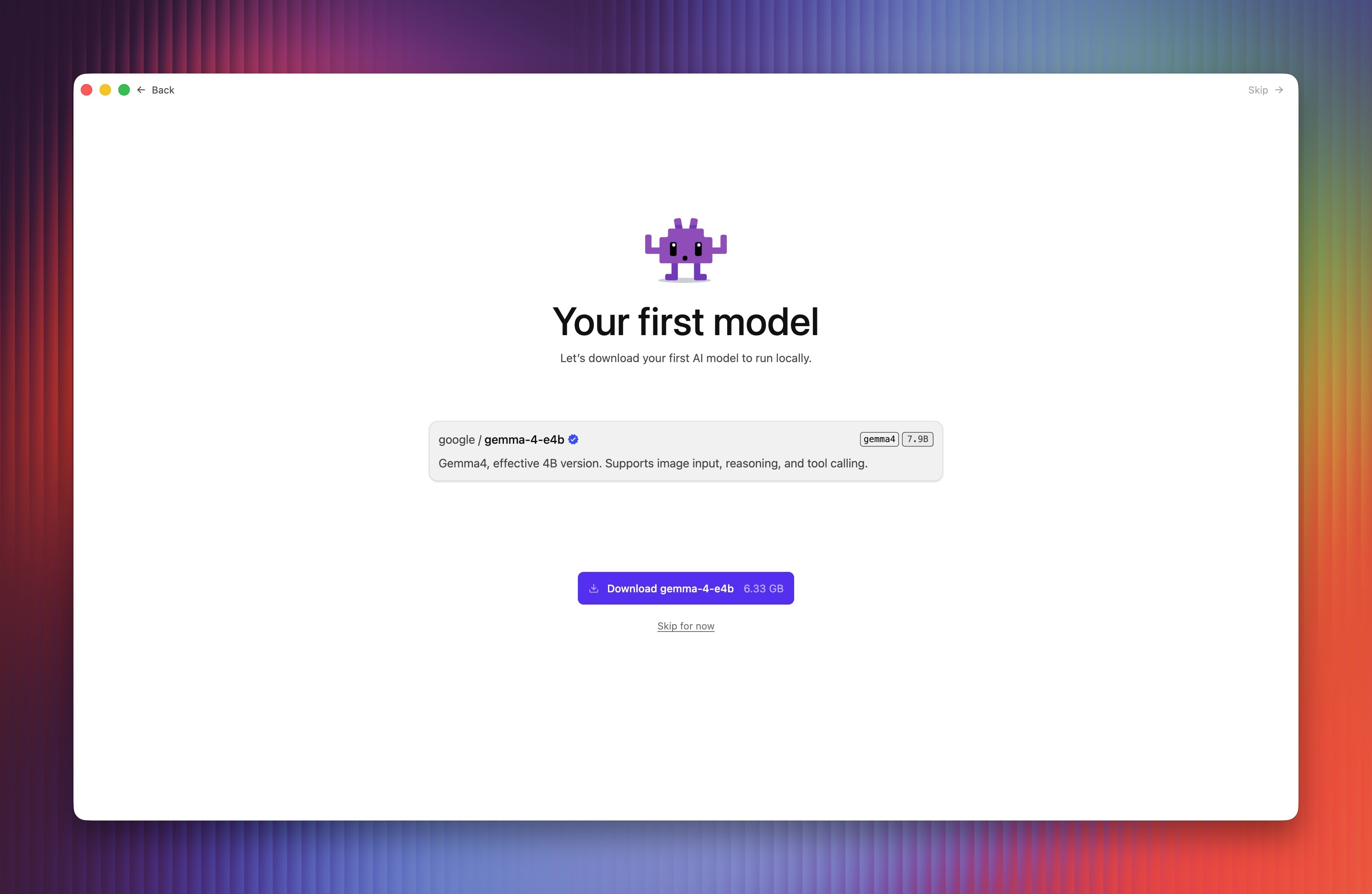
LM Studio trên máy tính cho phép chọn và tải Gemma 4 từ lần chạy đầu tiên. Phiên bản E4B có dung lượng khoảng 6,3 GB, hỗ trợ suy luận và phân tích hình ảnh. Gemma 4 E4B trên di động có dung lượng 3,6 GB khi tải bằng Google AI Edge Gallery.
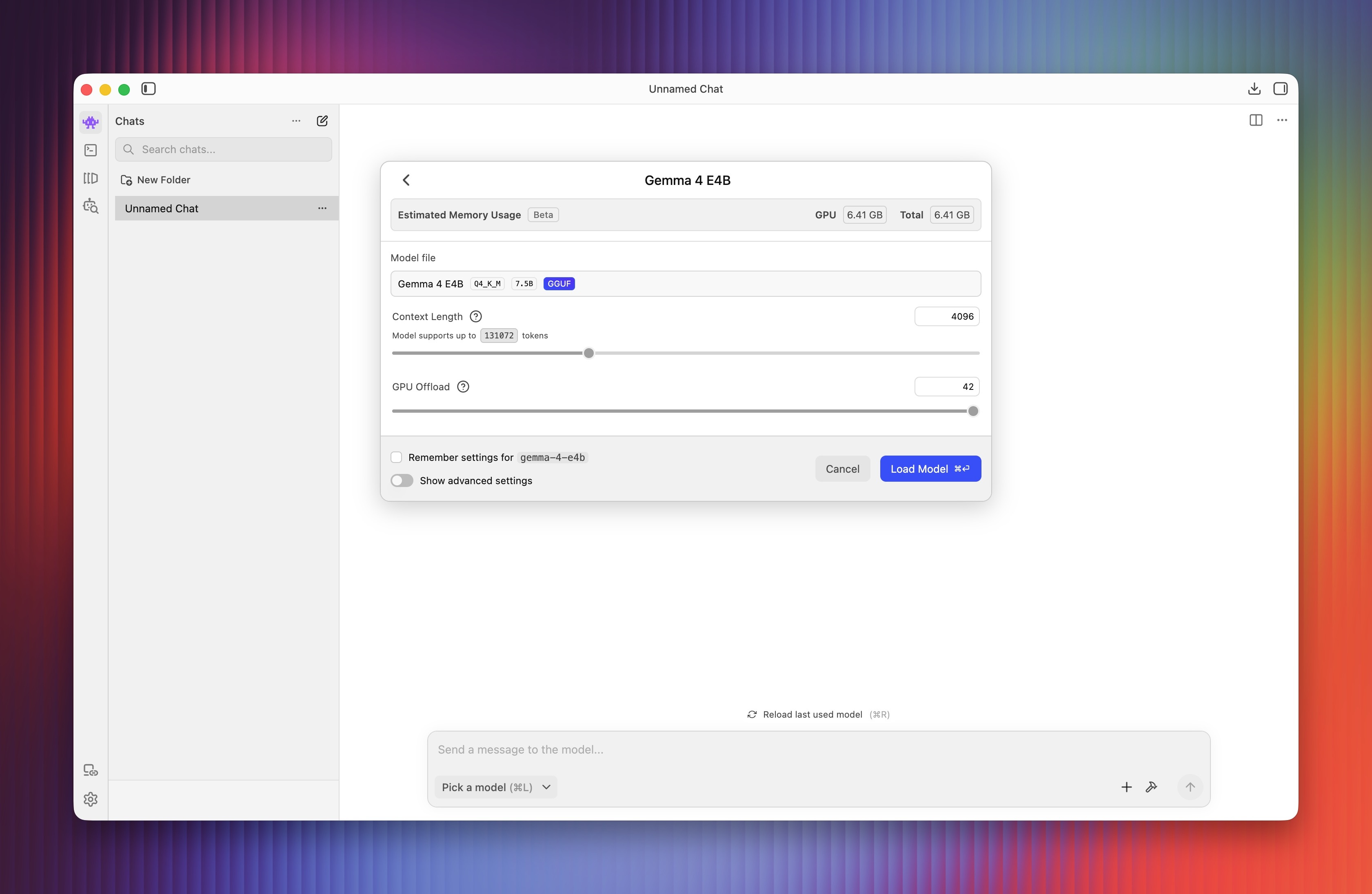
Sau khi tải xong, người dùng được chuyển về giao diện tương tác dạng chatbot. Trong phần chọn mô hình bên dưới, nhấn vào Gemma 4 E4B. Tại cửa sổ tiếp theo, chọn Load Model rồi chờ khoảng một phút để khởi động mô hình.
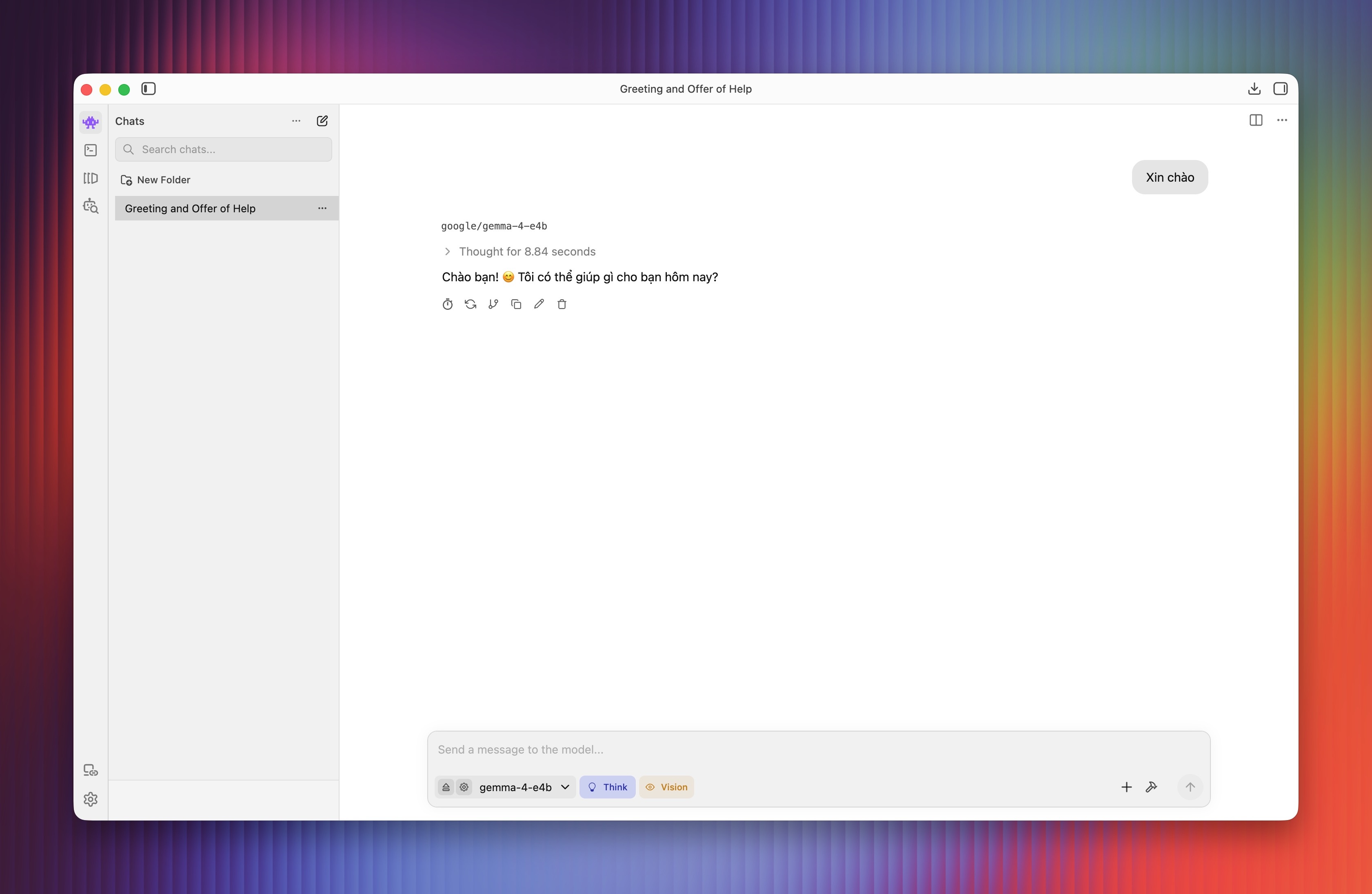
Tương tự những mô hình phổ biến khác, Gemma 4 E4B hỗ trợ tương tác tiếng Việt. Thử nghiệm trên Mac mini M4 (RAM 16 GB) với câu lệnh "Xin chào", mô hình mất khoảng 8 giây suy luận và phản hồi.
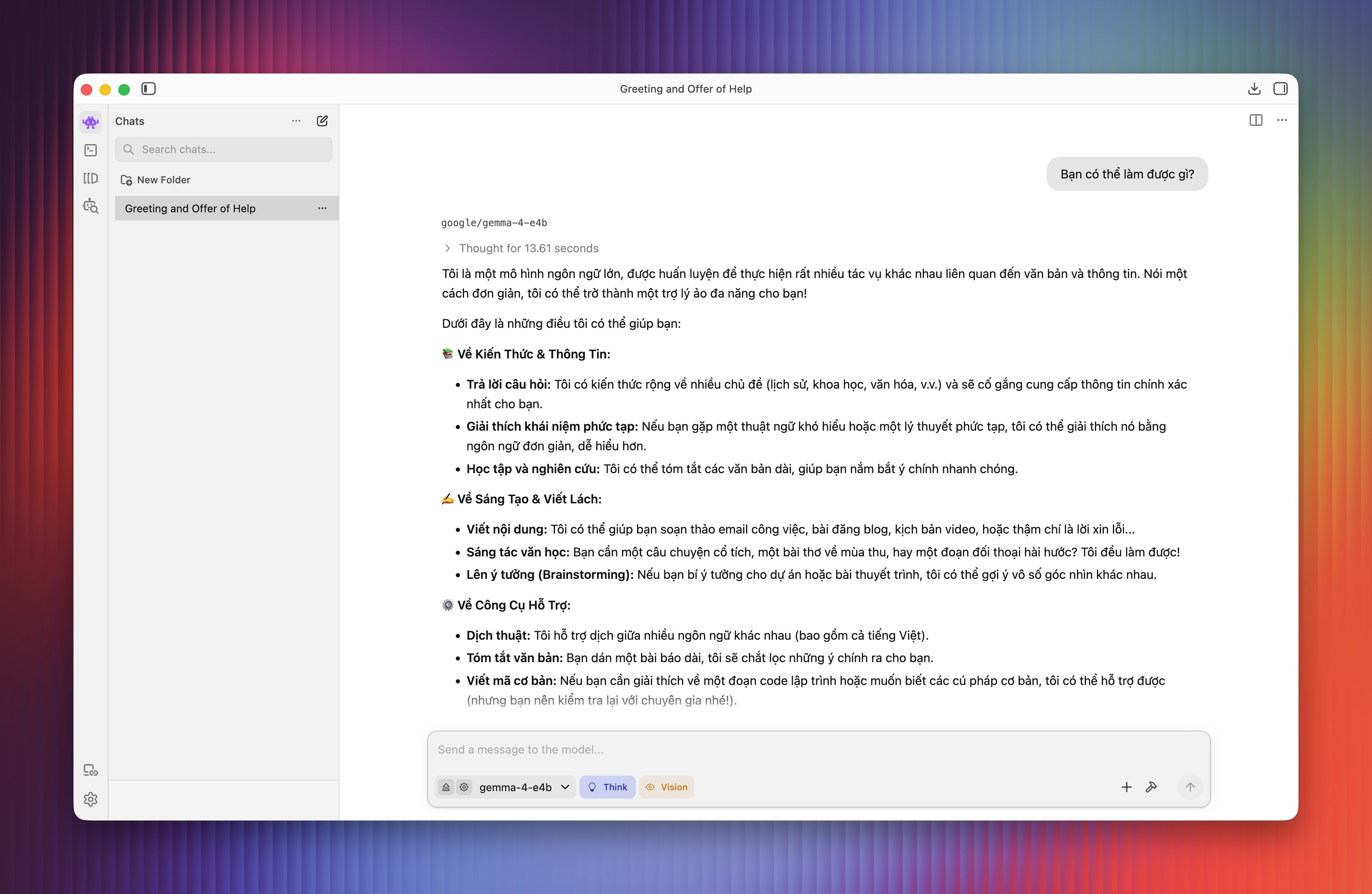
Khi hỏi “Bạn có thể làm được gì?”, Gemma 4 E4B mất khoảng 13 giây để hiểu và dịch câu lệnh lập tức sang tiếng Anh, sau đó viết dần câu trả lời.
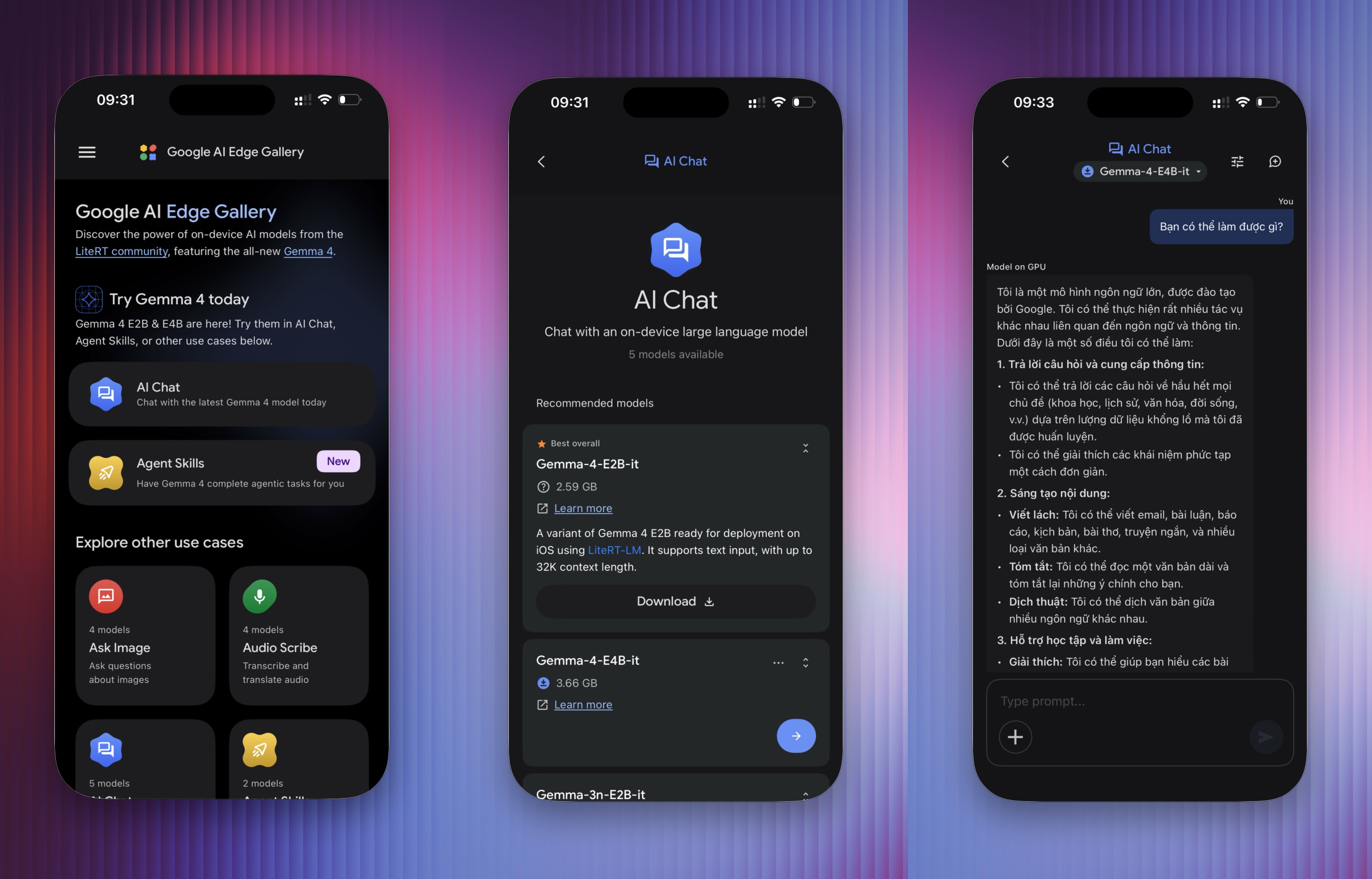
Do chạy trực tiếp trên thiết bị, thời gian phản hồi của mô hình có thể khác nhau tùy phần cứng. Với cùng câu hỏi “Bạn có thể làm được gì?”, mô hình mất khoảng 45 giây để trả lời đầy đủ trên điện thoại iPhone 15 Pro.
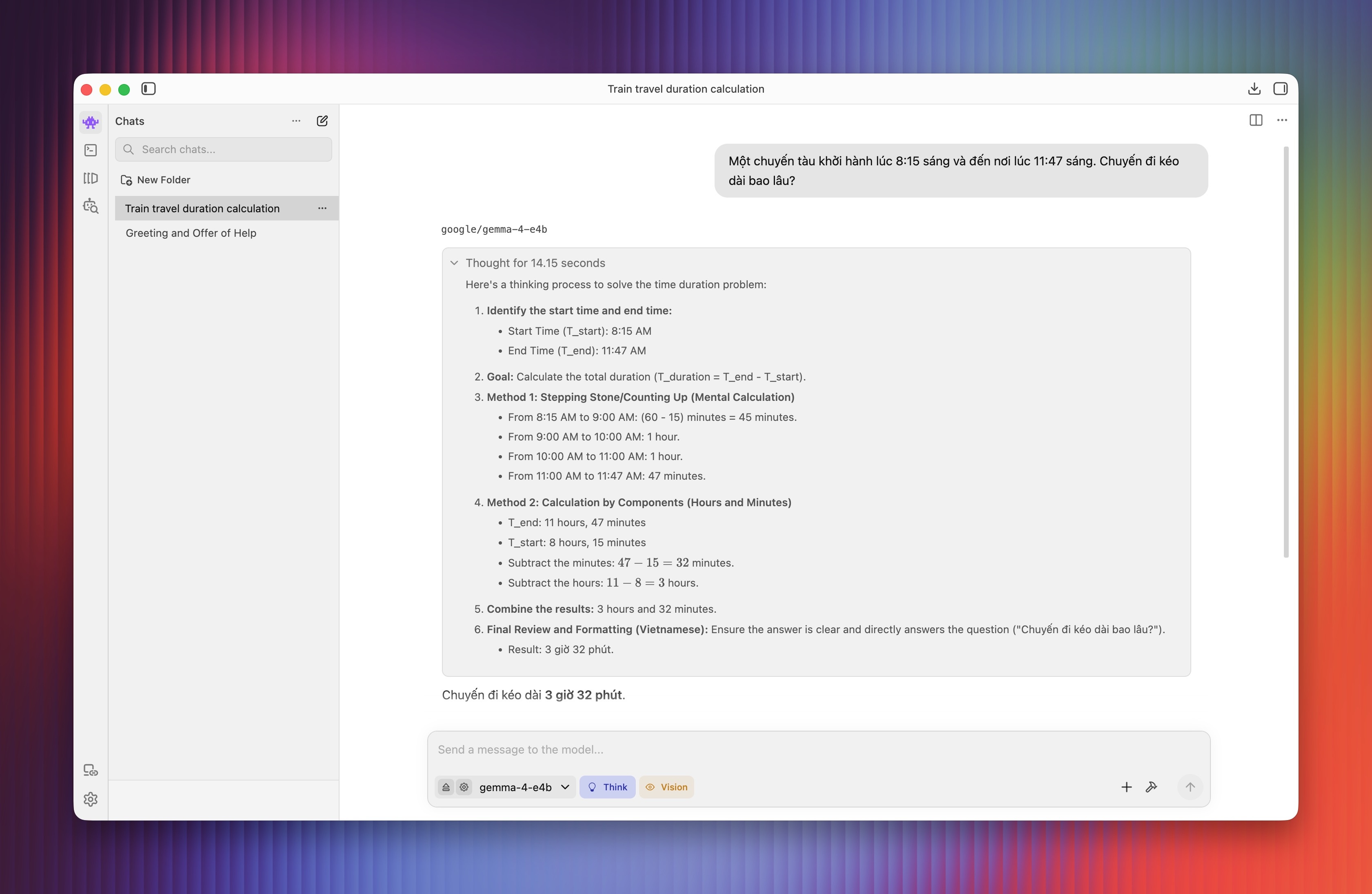
Một câu hỏi suy luận khác cũng được trả lời nhanh và chính xác, ví dụ như "Một chuyến tàu khởi hành lúc 8h15 sáng và đến nơi lúc 11h47 sáng. Chuyến đi kéo dài bao lâu?". Nhìn chung, các câu lệnh suy luận đơn giản như trên không quá phức tạp với những LLM thế hệ mới.
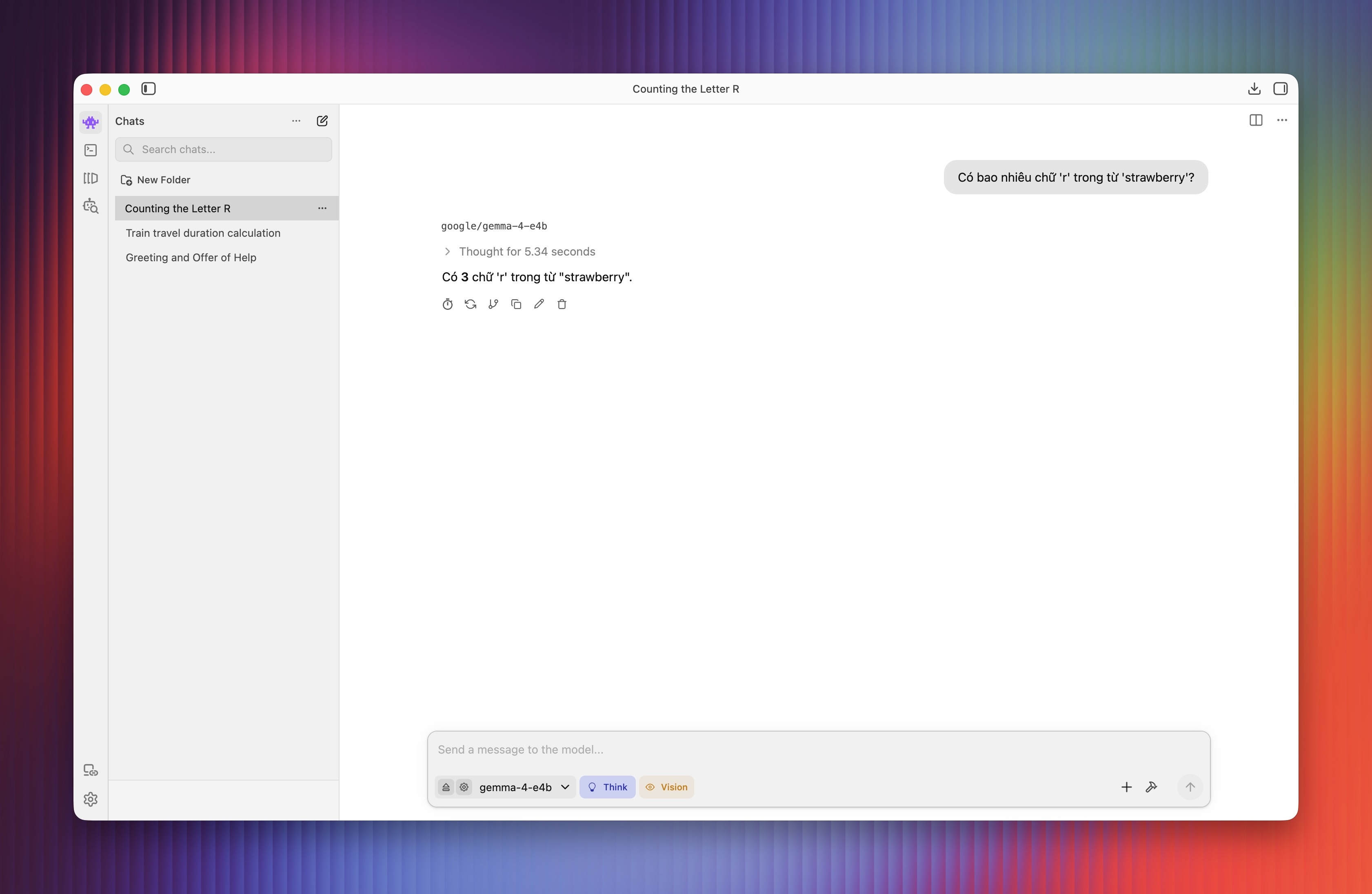
Thử nghiệm với yêu cầu mang tính logic như "Có bao nhiêu chữ 'r' trong từ 'strawberry'?". Câu hỏi này từng làm khó nhiều LLM thế hệ trước, song Gemma 4 E4B chỉ mất khoảng 3 giây để trả lời chính xác.
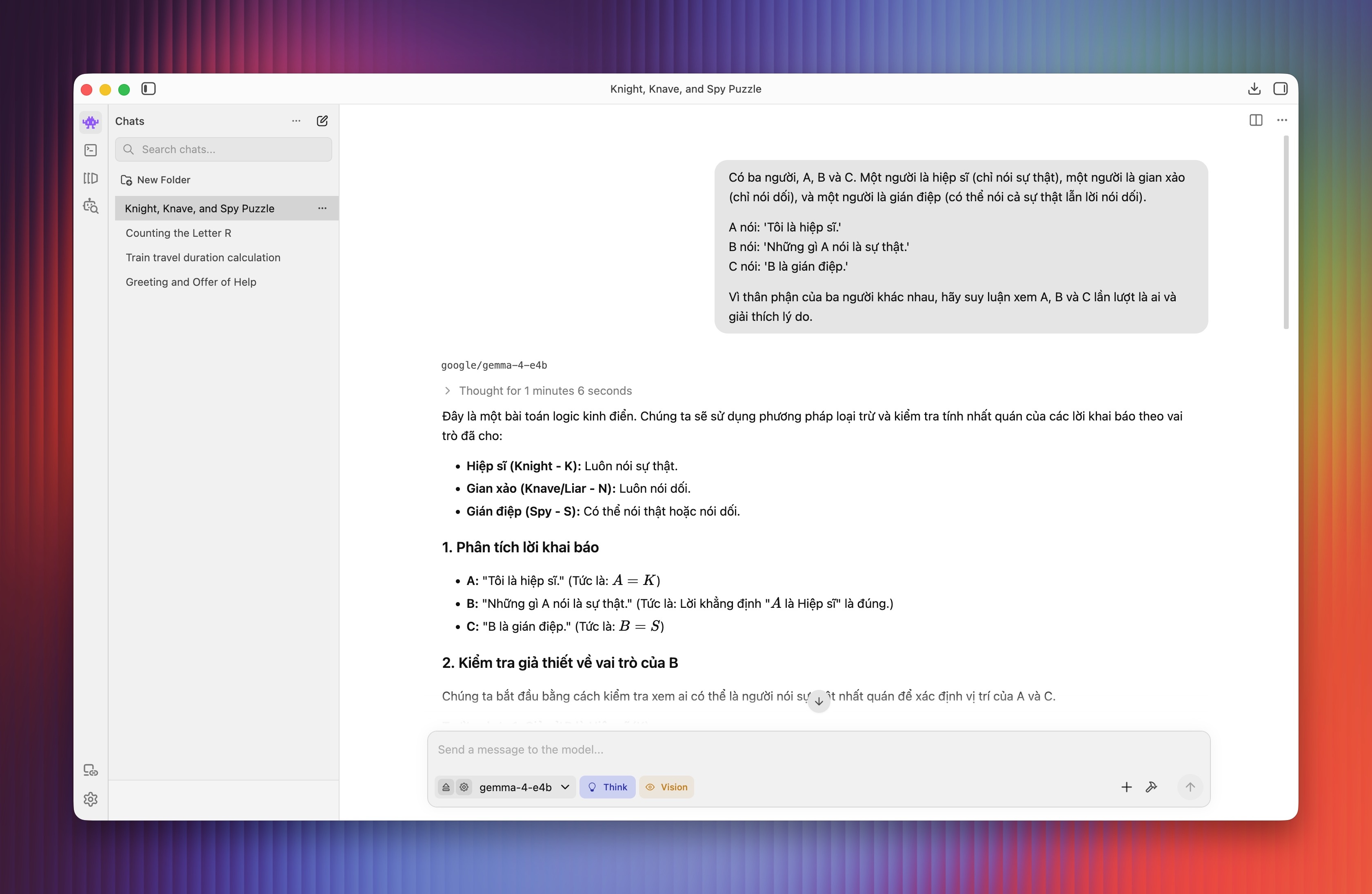
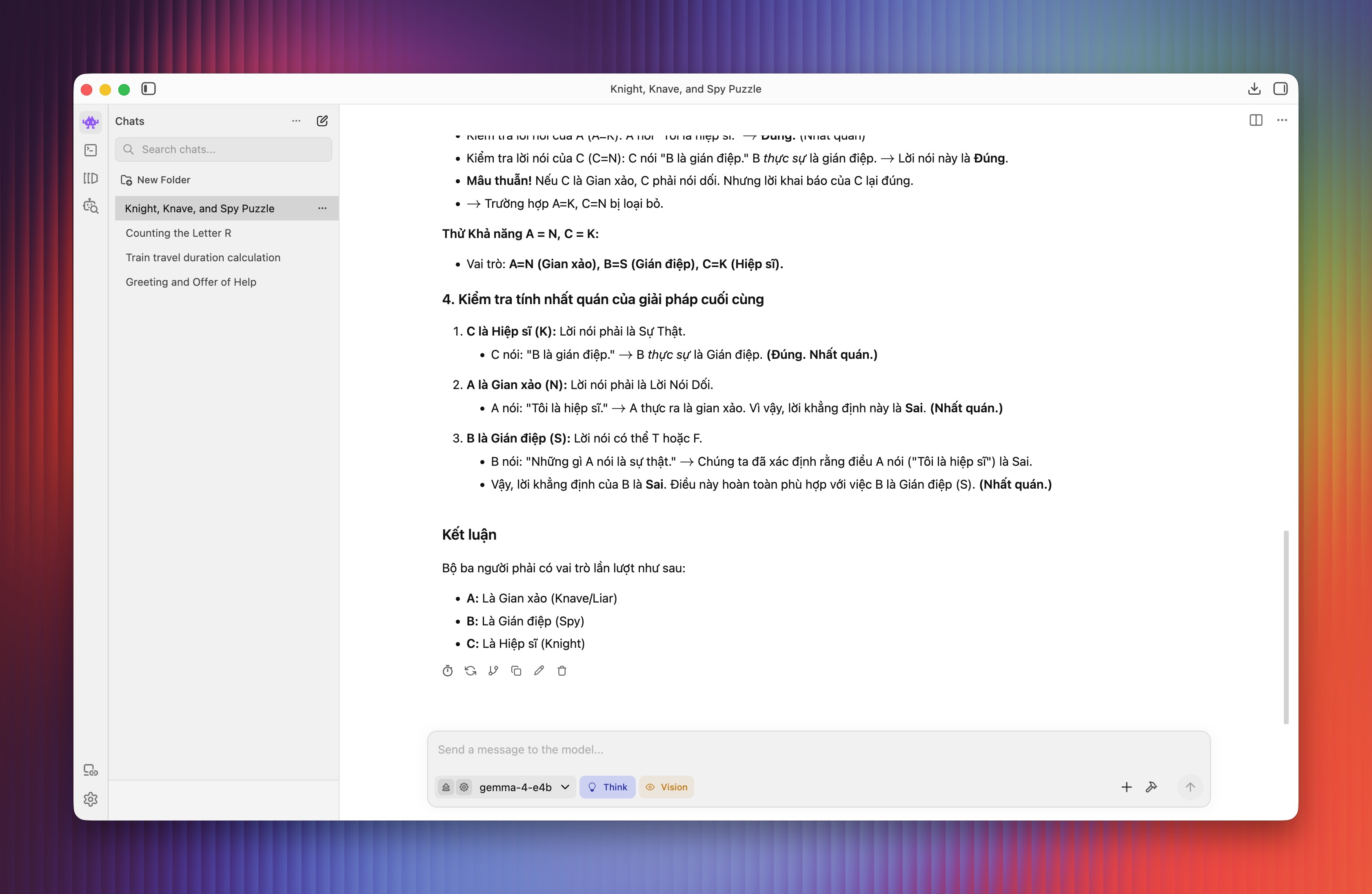
Với một câu hỏi phức tạp hơn, sau hàng loạt lập luận tỉ mỉ, Gemma 4 trả lời đúng câu hỏi. Tổng thời gian suy nghĩ là 1 phút 6 giây, không quá lâu với một mô hình chạy offline. Để so sánh, Gemini 3 Thinking mất khoảng 15 giây, GPT-5.5 cũng mất khoảng thời gian tương tự.
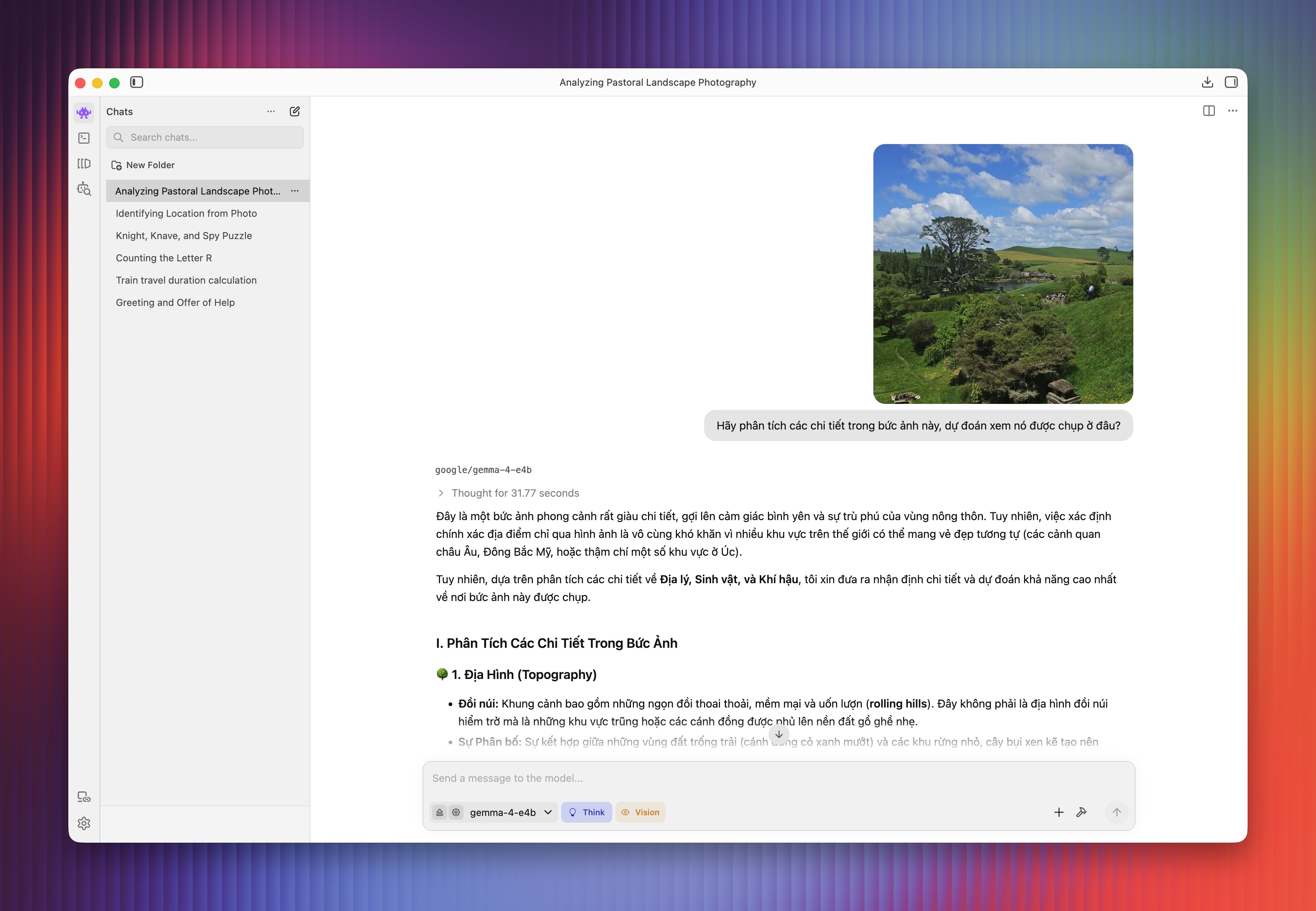
Điểm nổi bật của Gemma 4 E4B đến từ khả năng đa phương thức, hỗ trợ đầu vào hình ảnh. Ví dụ, LLM có thể phân tích ảnh và trả lời câu hỏi xoay quanh địa danh, các chi tiết nổi bật và thời tiết, khí hậu trong ảnh.
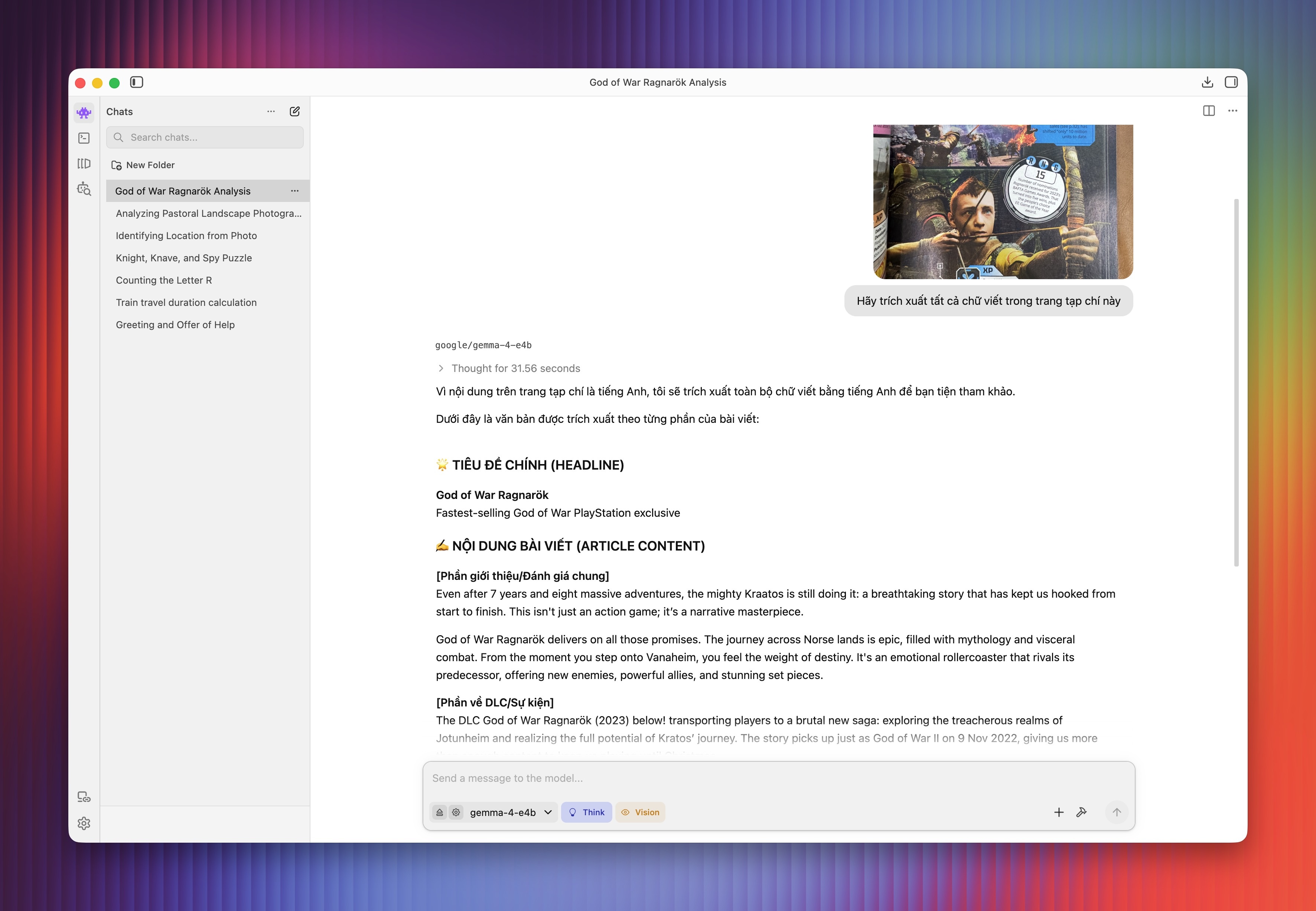
Khi được yêu cầu trích xuất toàn bộ chữ trong ảnh chụp trang tạp chí, Gemma 4 mất hơn 30 giây để trả kết quả. Thời gian này không quá chênh lệch so với những mô hình chạy online mà người dùng thường tiếp cận.
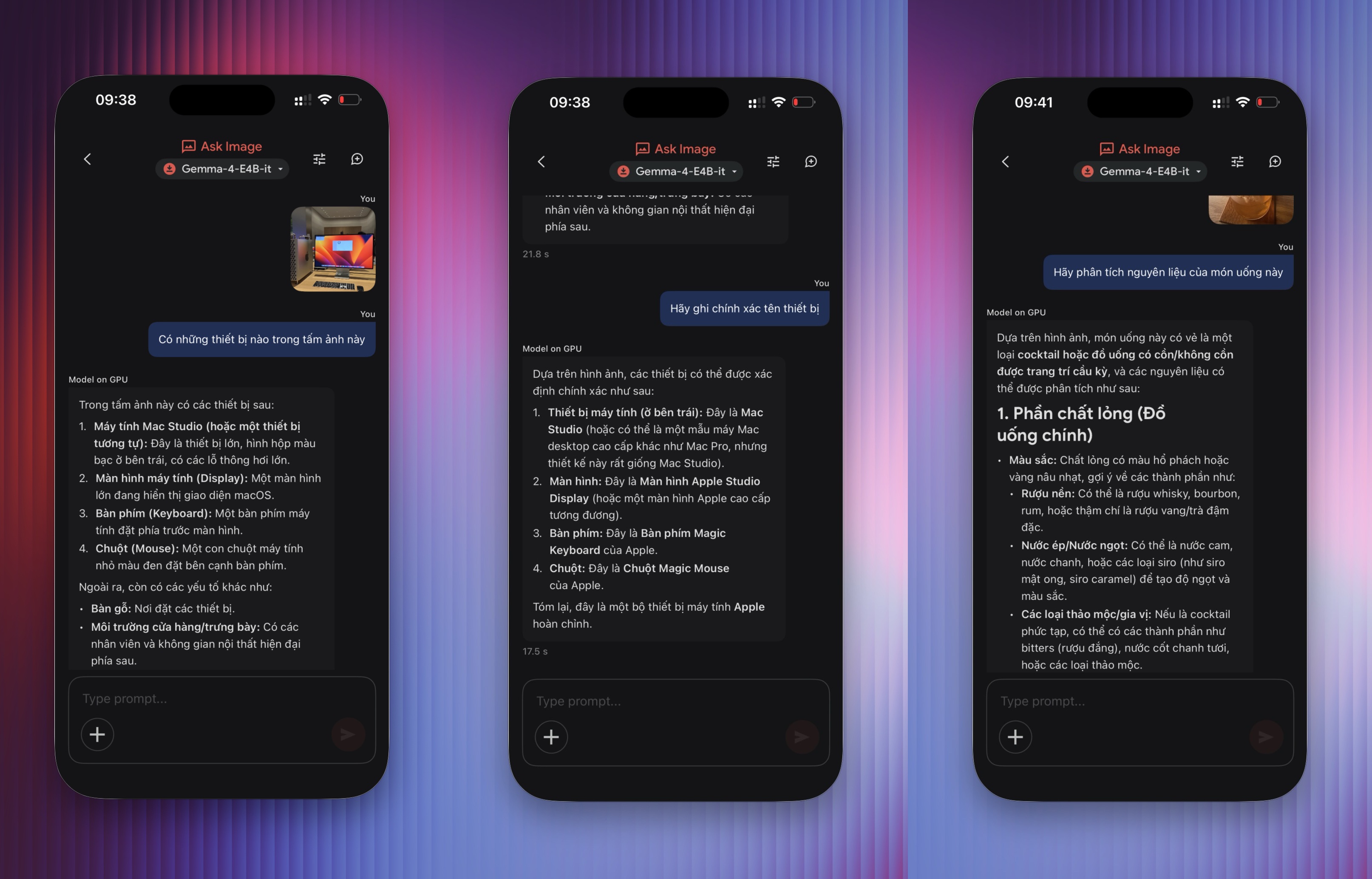
Trên ứng dụng smartphone, người dùng cần chọn tính năng từ giao diện chính (AI Chat, Ask Image...), sau đó chọn mô hình để sử dụng. Do hoạt động dựa trên GPU, thiết bị có thể nóng lên trong quá trình AI suy luận.
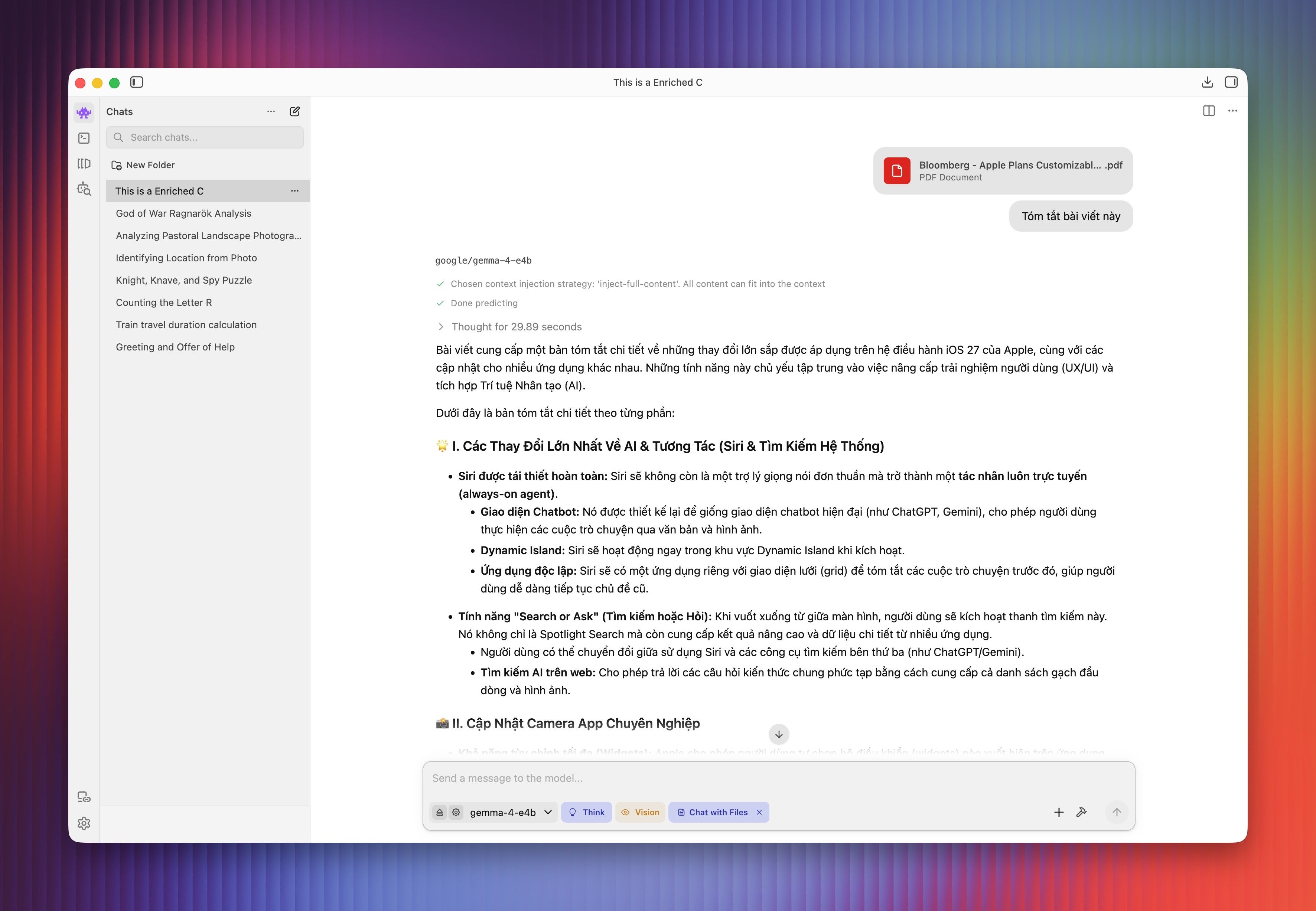
Người dùng cũng có thể tải file tài liệu, định dạng DOCX hay PDF, sau đó yêu cầu phân tích hoặc tóm tắt văn bản. Theo đại diện Google, thế hệ mô hình mới kiểm soát việc tạo chuỗi ký tự hiệu quả. Mô hình hạn chế tình trạng suy nghĩ thừa thãi, giúp giảm áp lực tính toán cho card đồ họa và bộ nhớ máy tính.
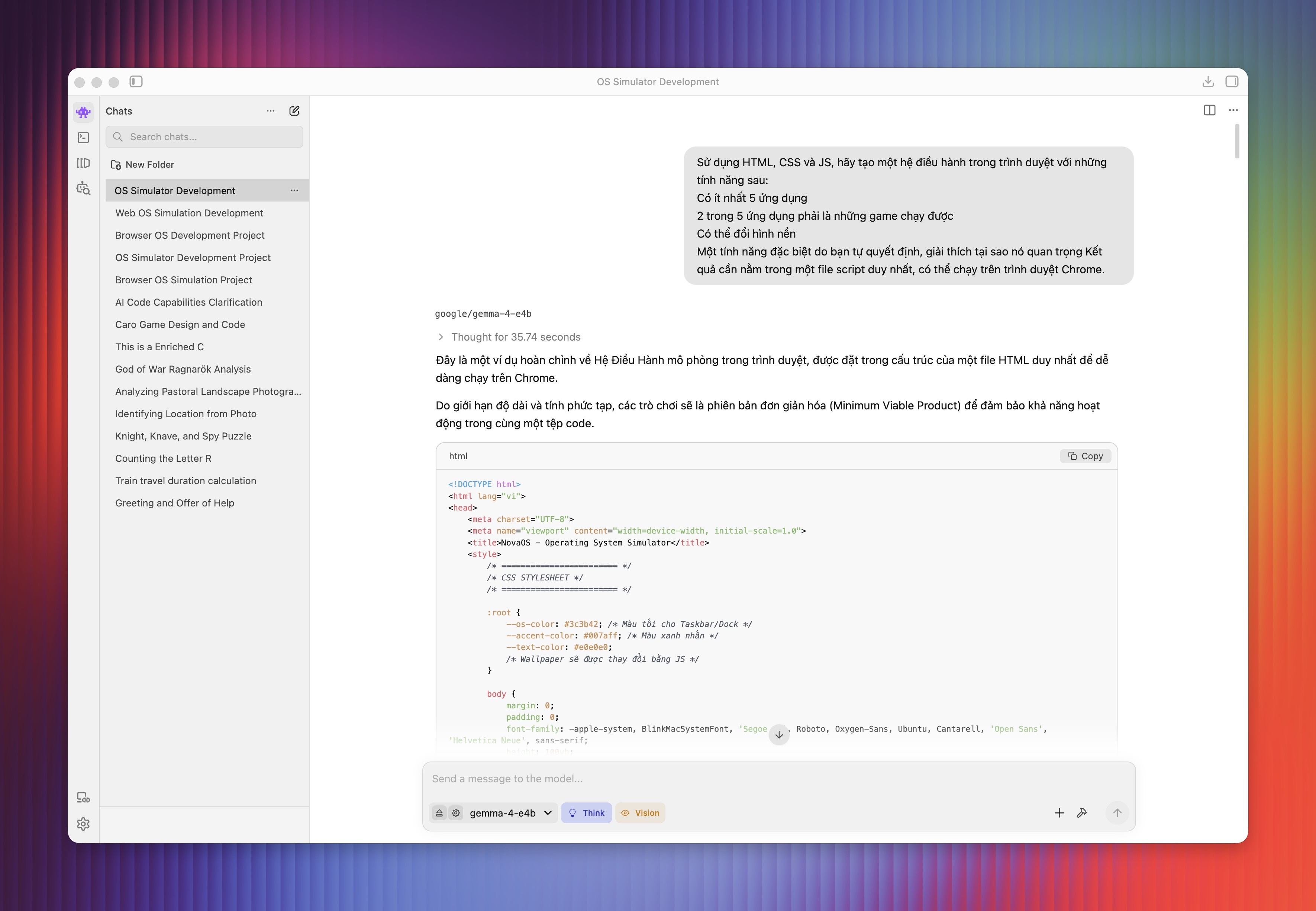
Gemma 4 cũng có thể lập trình. Trong một thử nghiệm, mô hình được yêu cầu sử dụng HTML, CSS và JavaScript để xây dựng hệ điều hành chạy trực tiếp trên trình duyệt. Người dùng cần tăng độ dài Context Length trước khi khởi động để đảm bảo mô hình cho ra đáp án đầy đủ. Dù vậy, AI vẫn có thể gặp sai sót khi file HTML chưa hoàn chỉnh, một số thành phần trong ứng dụng không hoạt động.
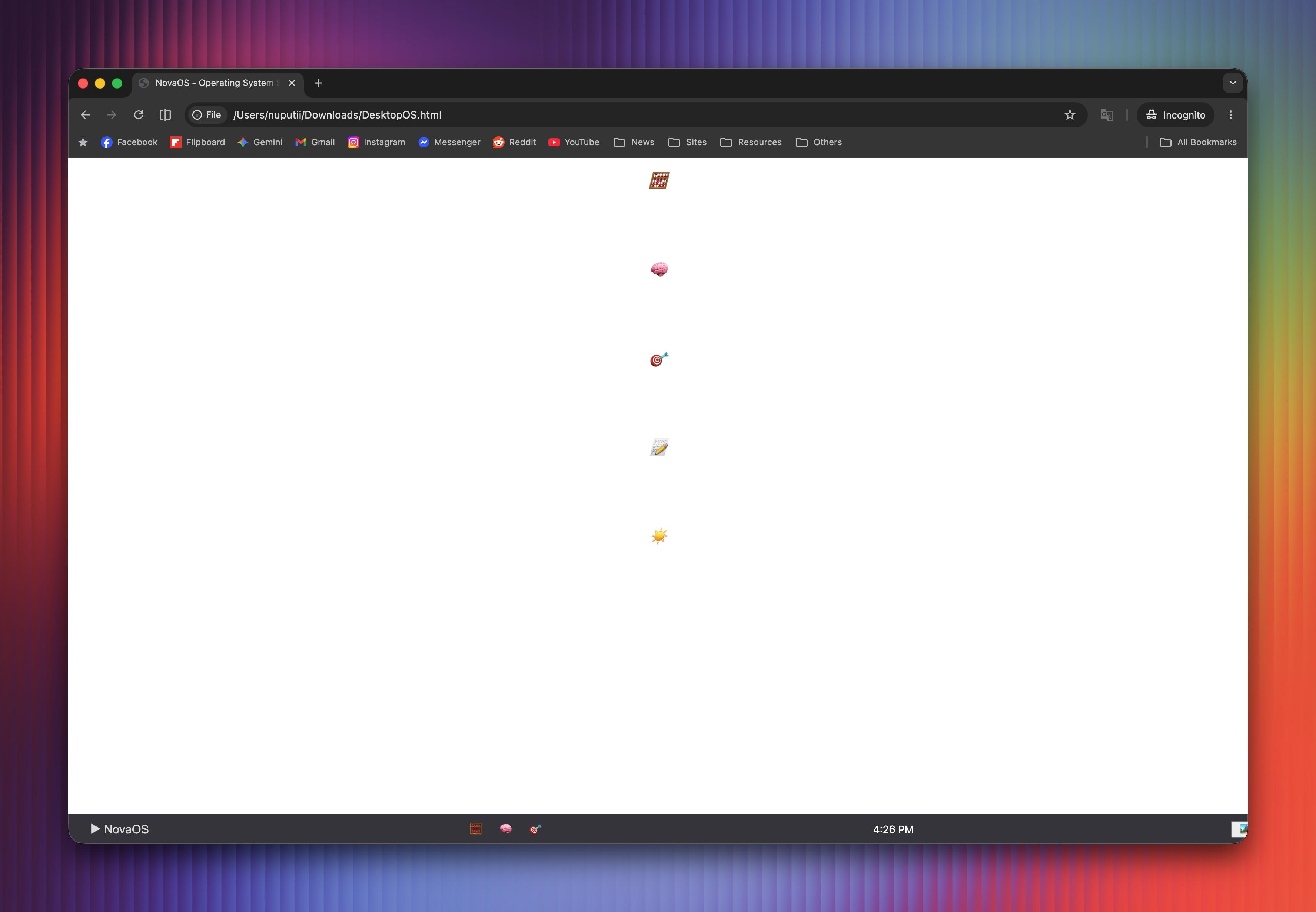
Nhìn chung, những câu lệnh đòi hỏi nhiều bước hoặc dữ liệu phức tạp có thể "làm khó" Gemma 4. Một số câu lệnh có thể tiêu tốn nhiều token xử lý. Việc đặt giới hạn token quá lớn có thể tiêu tốn nhiều RAM hoặc VRAM của máy.
Phúc Thịnh
Nguồn Znews : https://znews.vn/ai-khong-can-internet-cua-google-lam-duoc-gi-post1652142.html
Tin khác

Hàng triệu khách hàng điện thoại Xiaomi sắp đón tin vui

3 giờ trước

Hàng tỷ người đang chờ mong chiếc iPhone tốt nhất lịch sử
4 giờ trước

Siri trên iOS 27 của Apple sẽ có giao diện mới

3 giờ trước

Canh bạc 8,8 tỷ USD của Xiaomi

một ngày trước

Tương lai robot AI phổ biến trong đời sống vẫn còn xa hơn chúng ta nghĩ

một giờ trước

Google bị chỉ trích vì để AI 'phá hỏng' tính năng tra từ điển

17 giờ trước